Guía de navegación de Altamar
Un pequeño compendio que busca reunir información útil para quienes quieren alejarse de las injusticias éticas y monetarias que se nos imponen para poder disfrutar de las artes.
- Introducción
- Proyectos
- Configuración del servidor
- El router
- Adquisición y configuración de dominios
- Preparar el sistema operativo
- El Reverse Proxy
- Configuraciones específicas de Notebooks
- Usando el LVM
- Servicios
- Glosario
- Direcciones IP
- Puertos
- Dominios
- Permisos en Linux(y UNIX)
- La Terminal
- SSH
- Gestor de paquetes (Package manager)
- Docker
- ToDo
- Cockpit
Introducción
Hola, bienvenidx! Pasá por acá, sentate, ponete cómodx. Este libro que tenés enfrente tuyo es, como su nombre indica, una guía de navegación por las aguas del altamar, para quienes quieren:
- Despegarse de nuestras formas problemáticas de consumo
- Dejar de depender de servicios que, además de empeorar cada vez más y salir cada vez más caros, se van tornando día a día más en nuestros señores feudales o, directamente, en villanos de ficción
- Redefinir su relación con la propiedad de los medios(notaron que ya no somos dueñxs de la música que escuchamos?) o su soberanía digital(están tranquilxs descansando mientras google o apple pueden acceder, cuando quieran, a sus contraseñas?)
Esta guía está, todavía, siendo escrita. Así que no vas a encontrar todo lo que busqués acá(por ahora)
En esta guía, planeo ir de a poco delineando todos los conceptos fundamentales que se necesitan para poder armar lo que queramos relacionado al tema: Un "netflix" propio, con nuestros propios medios, un gestor de contraseñas, un "spotify" para la música que "ripeamos" de los CDs que aún tenemos(o que conseguimos de algún otro lado ;) ). La guía va a tener un caracter modular, por lo que podés acceder sólo a la información que necesites para armar lo que querés armar. En esta primera página, introductoria, planeo ir dejando un índice, y varios "caminos" a seguir, dependiendo lo que quieras armar. Si no hay algún link, es que todavía no existe ^^'
Qué necesito para hacer esto?
Un servidor
No hace falta mucho para reclamar, de una forma u otra, nuestra soberanía. Lo más difícil e importante que necesitamos es una computadora. Puede ser la que usamos todos los días, pero no sería lo ideal, ya que para poder acceder a las cosas que vayamos armando, lo ideal sería que sea una computadora que dejamos siempre prendida y conectada a la red de nuestra casa. Este tipo de computadoras se suelen llamar servidores, ya que son computadoras que existen para "servir" contenido a otras computadoras que actúan como "clientes".
Para estos tutoriales, debido a su reputación como sistema operativo de servidores y la baja cantidad de recursos que consume, vamos a estar usando Linux.
Qué tiene de especial un servidor?
En realidad, nada. Es una computadora común, sólo que la dejamos, como menciono antes, siempre prendida y conectada a nuestra red para que esté disponible a "atender" a los clientes que le conectemos. Hay varias computadoras que podemos usar de servidores, pero las más relevantes para quienes lean esto me parece que pueden ser:
- Una Raspberry pi
- Una notebook o compu de escritorio vieja
- La netbook que te dieron en la escuela que tenés tirada Por lo general, los "servicios"(programas para servir contenido) que instalamos en nuestros servidores suelen consumir pocos recursos.
En una laptop "vieja" que conseguí, con 8gb de ram y un intel i5 viejo, tengo los siguientes servicios corriendo:
- "Netflix" privado que uso yo y amgixs
- "Spotify" privado que uso yo y amigxs
- Gestor de contraseñas para mí y gente cercana
- Un par de foros
- Un par de bots de telegram
- Un programa de presupuesto
- "Trello" privado
- Esta wiki
- Varias cosas más
Un dominio
Un dominio no es algo completamente indispensable para un servidor, ya que con conectarse a la IP pública debería alcanzar. Sin embargo, la mayoría de los proveedores de internet no nos dan una IP pública fija, sino que de a ratos, y a criterios sujetos más bien a lo que define cada proveedor, nos la van cambiando. Por esto, lo mejor que podemos hacer es "alquilar"(ya que no se pueden comprar) un dominio que apunte hacia nuestra IP, y mediante procesos automatizados, ir actualizando la IP hacia la que apunta para que siga siendo la nuestra.
Índice de guías
Preparación previa
Lo primero que tenemos que hacer es preparar nuestro futuro servidor. Los pasos a seguir serían:
- Instalar Linux y los programas necesarios en dicho servidor
- Si queremos hacernos la vida un poco más cómoda, y sí o sí si queremos conectarnos a nuestros servicios desde fuera de casa(por ejemplo para usar nuestro "spotify" en la calle), obtener un dominio público (un dominio público que yo uso, por ejemplo, es "cuquiweb.xyz", donde me leen :) )
- Si queremos acceder al servidor desde fuera de casa, vamos a tener que configurar nuestro router
Guías de servicios
Entre las varias cosas que planeo enseñar, podemos:
- Armar nuestro propio "netflix"
- Armar nuestro propio "spotify"
- Guardar nuestras contraseñas en un espacio seguro.
Proyectos
En este capítulo se reunirán las "hojas de ruta" de varios proyectos, planteados de forma modular.
Armá tu propio "spotify"
Este artículo, por ahora, es sólo un boceto. A medida que vaya armando las notas necesarias, las voy a ir linkeando por acá.
Introducción
Vamos a armar un spotify
Prerequisitos
Como todas las guías acá, vamos a necesitar tener linux instalado y docker y docker compose. También vamos a necesitar python. También, si querés hacerlo accesible desde afuera, vas a necesitar configurar tu router, obtener y configurar un dominio y configurar un reverse proxy. También, si instalamos el LVM cuando instalamos el sistema operativo, nos va a convenir crear un volumen específico en el que guardar nuestra música. Por último, puede ser útil tener instalado cockpit en nuestro servidor como forma simple de subir archivos de música de nuestra computadora, si es que tenemos música ahí para subir.
Hoja de ruta
Optativo
Conseguir música
- Instalar spotdl
- Instalar slskd
Administrar música
- Instalar musicbrainz Picard
Abrir el servidor
- Nota de abrir el servidor
Acceder mediante aplicaciones
- Listado de aplicaciones para acceder a Navidrome
Instalar Navidrome
Configuración del servidor
En este capítulo vas a encontrar todos los artículos respecto a la preparación del servidor para cosas como:
- Exponerlo al internet público
- Instalarle los componentes necesarios para correr los servicios
- Y más
El router
Preparar nuestro router para conexiones externas
Sinopsis
Cuando utilizamos una computadora como servidor, sea para acceder y depositar archivos o para acceder a servicios, normalmente la conectamos a nuestra red local de casa, gestionada por nuestro Router, el cual en muchos casos nos es proveído por nuestra empresa de internet (o ISP).
Para qué sirven los routers
Estos aparatos hacen varias cosas, entre ellas: Gestionan nuestra red local(permiten que nuestras computadoras y dispositivos se conecten entre sí), y nos permiten conectarnos a internet. Cada vez que cargamos una página o bajamos un video, nuestra computadora le está pidiendo a nuestro router que nos ponga en contacto con la máquina que tiene dicha página o video. En este sentido, el router es el punto único de conexión entre nuestras computadoras en nuestra casa y las demás computadoras del mundo conectadas a internet.
Además de esto, es a través del router otras computadoras de internet hablan con las nuestras. Normalmente esto ocurre cuando nuestras computadoras se ponen primero en contacto con una compu de afuera: Si queremos revisar el mail, cuando cargamos la página somos nosotrxs quienes pedimos a la compu de afuera que tiene nuestros mails guardados que nos los mande para que los podamos leer, por ejemplo.
Sin embargo, para poder acceder nuestra computadora desde afuera, necesitaríamos poder indicar de alguna forma al router, que recibiría la conexión, que "derive" el pedido de la computadora de afuera a una computadora en específico, en este caso nuestro servidor. De esta manera, cuando una computadora externa (como, por ejemplo, nuestro celular cuando no estamos conectadxs a la red wifi o local) se conecta a nuestra IP pública, nuestro router la guía a la IP local de nuestra red.
Por lo general, esto no es algo que nuestros routers hagan por defecto: Todas las comunicaciones que tenemos a interent, por defecto, las llevamos a cabo desde nuestra casa hacia afuera por cuestiones de seguridad. Para poder hacer que nuestro router "derive" estas conexiones cuando son originadas desde afuera, tenemos que indicarle que lo haga. Para esto vamos a redirigir conexiones a puertos específicos: Esto se llama hacer "port forwarding".
Al final del camino, esta secuencia de conexiones externas se vería de la siguiente forma:

En la que una computadora de afuera se conecta con nuestro router a un cierto puerto; nuestro router, al detectar que se conectó a ese puerto, redirige la conexión a la IP local de nuestro servidor.
Hay dos cosas, entonces, que nos conviene hacer:
- Configurar nuestro router para exponer un puerto al exterior.
- Configurar nuestro router para que le de una IP local específica a nuestra computadora.
Tutorial: Cómo configurar el router para exponer un puerto
Cuando queremos exponer la conexión de una de nuestras computadoras hacia el exterior, tenemos que configurar nuestro router. Esto, a veces, se puede hacer directamente desde la página de nuestro proveedor de internet, pero muchas veces no es el caso. Por este motivo, este tutorial se va a centrar en cómo hacerlo a través de nuestro router directamente.
Esta sección es una de las más complejas, ya que los distintos modelos de routers y gateways suelen tener sus propias convenciones de nombres. Intento ser lo más exhaustivo que puedo, pero es posible que tengas que googlear un poco sobre tu router y proveedor de internet específico.
Acceder al router
Lo primero que tenemos que hacer es acceder a la página de configuración de nuestro router. Para esto, necesitamos obtener la IP local del router. Por lo general esta puede ser alguna de estas tres:
- 192.168.0.1
- 192.168.1.1
- 10.0.01
Si no te funciona ninguna de ellas, podés usar los siguientes comandos:
En Windows
En el "Símbolo de sistema"(CMD) de widnows, escribí el siguiente comando: ipconfig, y buscando la ip al lado de "Default Gateway"
En MacOS
En la terminal de mac(la podés abrir desde el spotlight), con el comando netstat -nr | grep default
En Linux
En la terminal de Linux, con el comando netstat -r | grep default
Login
Este es un punto potencialmente complejo. Por lo general, la mayoría de los routers nos los instalan con las credenciales por defecto, por lo que cosas como:
| Usuario | Contraseña |
|---|---|
| admin | admin |
| admin | |
| admin |
... suelen funcionar, o incluso no llenar ninguno de los dos campos. Sin embargo, en el mío, por ejemplo, el usuario por defecto era admin, pero la contraseña era cisco. Recomiendo googlear algo como "cuál es la contraseña por defecto del router
Por lo pronto, una vez que tengan esa información, pueden ingresar con su navegador a la página http://
Al ingresar la información de login vamos a poder ingresar al panel de control del router. En esta página, vamos a tener que buscar la sección de "Port Forwarding", que puede figurar de varias formas:
- En secciones como "Forwarding" o "Port Forwarding", a veces en subsecciones como "Virtual servers"
- En secciones como "Applications", o "Applications and gaming", ya que son cosas que se hacen normalmente cuando una persona quiere "hostear" un server de videojuegos.
En el caso de mi router, el menú en el que encontramos esto es el de "Applications & Gaming". El submenú donde encontramos la opción se llama "Port range forwarding". Fíjense que no siempre son exactos los nombres:
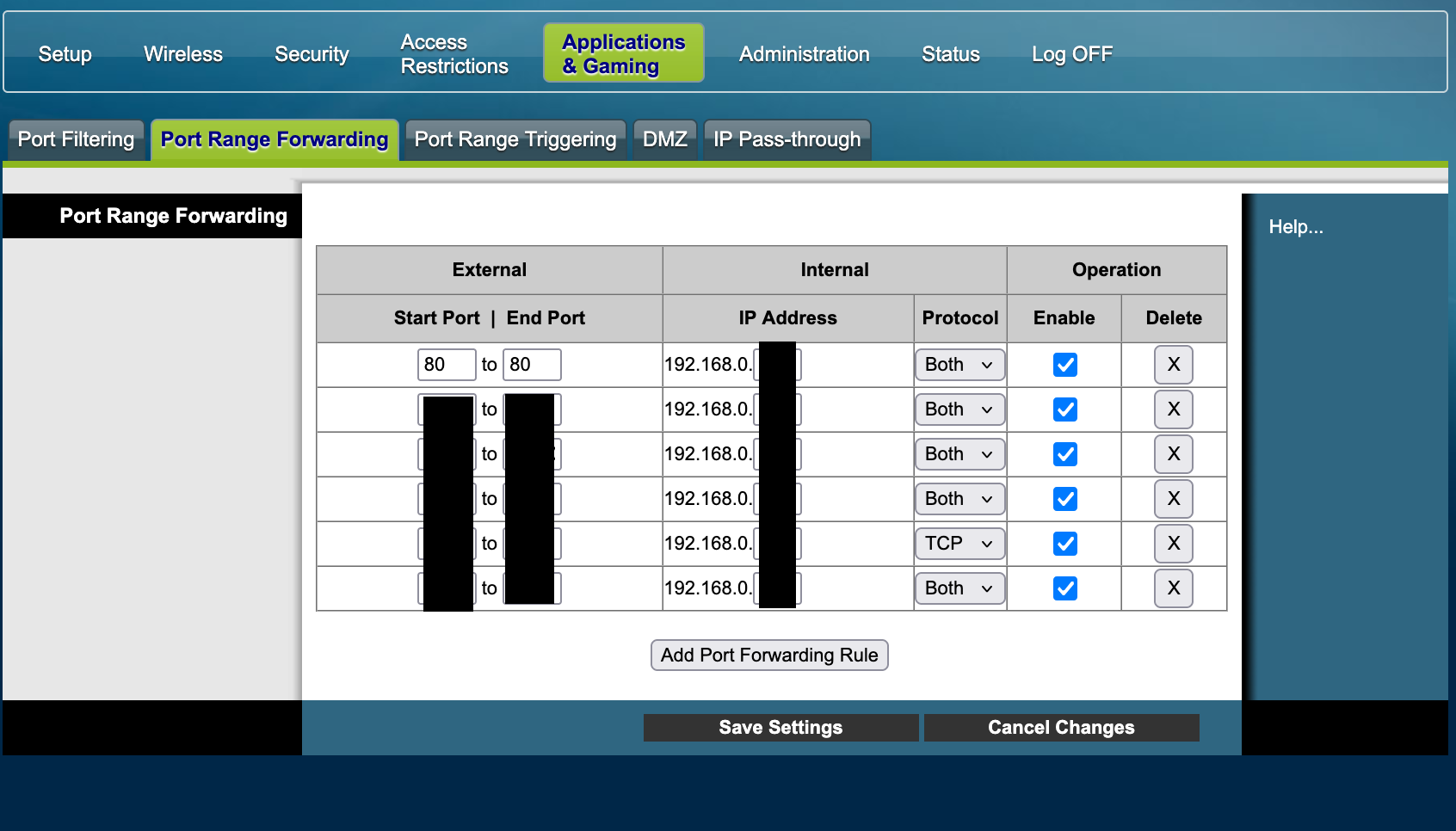
En este menú, podemos ver cómo le puedo indicar al router, cuando recibe una conexión externa en un puerto específico(en mi caso un rango de puertos), que la redirija a una IP local en particular.
Al hacer esto, cuando alguien se quiera conectar a nuestra IP, y lo haga en un puerto en particular(todas las conexiones ocurren en un puerto), nuestro router la redirige a una ip, idealmente la de nuestro server. Por otro lado, también nos puede ser útil configurar nuestra computadora para que tenga una IP local específica, ya que si no, por defecto, cada vez que se vuelva a conectar a la red(cuando la reiniciemos, por ejemplo) nuestro router le va a asignar una nueva IP.
Tutorial: Cómo configurar la computadora para tener una IP estática
Este tutorial, por suerte, es mucho más simple, ya que se puede hacer desde la computadora misma: Simplemente tenés que ir a la configuración de tu red(que, por lo general, es la configuración de la conexión a la red que estás conectadx), buscar el menú de IPv4, seleccionar modo Manual, y agregar una ip que esté en el rango de tus ips locales(por ejemplo, si tu router está en 192.168.0.1, cualquier ip entre '192.168.0.2y192.168.0.255` debería estar bien).
Dejo un tutorial de cómo hacerlo en linux, pero por lo general esto es bastante simple. Si vas a googlear cómo hacerlo en linux, te recomiendo googlear cómo hacerlo en tu distribución en específico: Es mejor buscar "how to set local static ip address in ubuntu/mint" que "how to set local static ip address in linux". De todos modos, el proceso es bastante similar en casi todos los sistemas operativos.
Adquisición y configuración de dominios
En esta página voy a explicar el proceso de alquilar un dominio y de "apuntarlo" a nuestra IP pública para facilitar el acceso externo a nuestro servidor.
Esta sección no fue escrita todavía
Preparar el sistema operativo
Esta página tiene como fin enseñar a instalar Linux en nuestro futuro servidor. Las guías se encuentran más abajo. Arriba, primero, un poco de contexto:
Esta sección no fue terminada todavía.
Qué es Linux?
Linux (o, mejor dicho, GNU/Linux) es un sistema operativo. Esto significa que es una serie de "programas" y "herramientas" armadas para servirnos para interactuar con nuestra computadora. Un programa para copiar un archivo en otro lugar, un programa para crear un archivo, etc. No son "programas" como un navegador de internet. Un navegador de internet suele usar varios de estos "programas básicos" para cosas como: Conectarse con otra computadora, descargar la página web y escribirla en nuestro disco, leer el contenido de esa copia para poder visualizarlo.
Un sistema operativo, esencialmente, es la capa que está entre el mundo digital de unos y ceros y el usuario, sobre el cual corren todos los programas que normalmente usamos en nuestro día a día. Cuando corremos, por ejemplo, un navegador de internet, el programa habla con el sistema operativo, y es este último el que actúa de intermediario y le dice a la computadora "qué hacer", qué cuentas hacer, qué píxeles de la pantalla prender, etc.
GNU/Linux es un sistema operativo ya con muchos años que, a diferencia de Windows o MacOS, que son sistemas de "código cerrado", es de "código abierto": Esto significa que, por un lado, todo el mundo puede ver cómo fue armado, y por lo tanto se puede corroborar más allá de cualquier nivel de conifanza qué pasa "abajo del capó" cuando corre. Por el otro lado, también significa que estos proyectos son de índole colaborativa: Cualquiera a quien le interese puede "sumarse" y aportar código, sean funcionalidades nuevas, arreglo de bugs, o lo que sea.
GNU/Linux suele venir en "distribuciones", o "distros", que son "paquetes" que se arman sobre esta base del sistema operativo con varios componentes extra comunmente usuados en el día a día, como un gestor de paquetes(app store, en resumen), un reproductor de vídeo, una interfaz visual para lx usuarix, etc. Estas distribuciones, estos "empaquetamientos" de linux, suelen mantener su filosofía de software libre, aunque no siempre es así, y no siempre lo hacen en la misma medida (Ubuntu, por ejemplo, a veces usa código "cerrado" en cosas como los drivers de placas de video, etc.). Varios distros conocidos y muy usados incluyen:
- Ubuntu
- Linux Mint
- Fedora
- Arch
Cada uno con su propia idiosincracia, pero siempre con la "base de programas" de GNU/Linux (los mismos programas para copiar archivos, para moverlos, etc)
Por qué linux?
Quizás quienes lean esta guía estén acostumbradxs a utilizar en el día a día otros sistemas operativos como Windows o MacOS. Estos suelen ser una opción elegida con frecuencia por estar pensados para ser utilizados en computadoras de uso personal, y suelen ser los entornos que estamos acostumbradxs a usar en el día a día. Hay varios motivos por los que elegir Linux, como el hecho de que Windows recolecte por defecto un montón de información privada sobre cómo lo usás. En este caso, sin embargo, voy a enumerar un par de criterios, algunos de elección personal y otros más objetivos, por los que elijo escribir esta guía usando un entorno de Linux:
- Es gratis: Los sitemas operativos de Linux son gratuitos. Si bien esta es una guía de altamar, la connotación que esto tiene también es una práctica: Cuando Windows "se da cuenta" de que tenés instalada una versión "no oficial", puede ponerse bastante gede.
- Es libre: Esto no sólo significa que es gratis, sino que también es una alternativa creada colaborativamente, en la que el código, cómo está hecha cada cosa, es abierto. Esto implica que quien quiera pueda mirarlo y asegurarse de que no pasa anda raro, como que te roben datos o usen recursos de tu computadora para minar crypto. Esto no significa que sea infalible; pueden haber virus en cualquier sistema operativo, y en muchos casos las aplicaciones de código abierto no son lo suficientemente grandes como para que sean revisadas por suficiente gente como para que sean 100% seguras. Pero en muchos casos los proyectos son lo suficientemente grandes como para que esto pase, y además, considero ideológicamente que la filosofía del Software Libre es ampliamente mejor que la del software cerrado y con fines de lucro para la humanidad.
- Es mejor para los servers: Linux es el sistema operativo utilizado por la mayoría de los servers del mundo. Los programas que vamos a usar, como Docker, suelen funcionar mejor en Linux porque, en este caso, la máquina por defecto en la que se piensa cuando piensan estos programas corre Linux.
- Es mejor para nuestra alfabetización digital: Estar en contacto con las cosas que vamos a estar armando contribuye mucho a poder entender mejor qué pasa en las computadoras cada vez que usamos un servicio como Netflix, Whatsapp, o cualquier cosa. Creo que entrar en contacto con estos conceptos, y "por ósmosis" ir entendiendo lo que pasa detrás, contribuye a la soberanía que tenemos sobre nuestra información(además, obvio, de la soberanía que queremos tener sobre nuestros medios y cómo los consumimos).
Guía: Preparación de nuestro server Linux
Instalar Linux
Instalar linux parece algo súper intimidante, pero la realidad es que es un proceso que se fue haciendo mucho más fácil en los últimos años de lo que creeríamos. Hay una cosa muy importante a tener en cuenta al hacerlo, que es que:
Al instalar linux siguiendo estos pasos, vas a estar borrando por completo toda la información que tengas almacenada en la computadora que estés transformando en server, por lo que es muy importante que antes de hacerlo copies toda la información importante (fotos, videos, documentos) que no quieras perder en algún otro lado (como en tu computadora principal).
Teniendo esto en cuenta, los pasos en sí son muy tranquilos y seguros. Repasemos cuáles son. Ante todo, vamos a necesitar:
- Una copia del sistema operativo
- Una memoria USB (donde entre dicha copia; la de ubuntu, por ejemplo, es de 3 GBs, así que con cualquier memoria más grande estamos bien)
- Una computadora a la que instalarle el sistema operativo :p
Armar el "Live USB"
Lo primero que vamos a tener que hacer va a ser conseguir una copia del sistema operativo que queramos instalar. En este caso, vamos a usar una distribución de Ubuntu. Ubuntu tiene algunas polémicas respecto a hacia adónde apunta la compañía en sí, y el hecho de querer usar bastante software propietario (no de código libre) en cosas como los drivers, pero a su vez es uno de los sistemas operativos más usados por lejos para armar un server, lo cual hace muy fácil googlear ante cualquier problema que tengamos.
Ante todo, vamos a necesitar descargar la edición para servidores de Ubuntu, que encontramos aquí. Recomiendo bajar la última opción disponible, por lo general (la última que nos muestra por defecto es la última "LTS" (Long Term Support), es decir la última versión estable y con soporte activo de por lo menos 5 años (después de los cuales podemos seguir usando esa versión, sólo no va a ser soportada por Canonical, la empresa de Ubuntu. Las soluciones vendrían de otrxs usuarixs o unx mismx).
Una vez que se termine la descarga, vamos a tener un archivo .iso, con un nombre similar a ubuntu-24.04.03-live-server-amd64.iso (los números pueden cambiar con distintas versiones, por ejemplo). Este archivo vamos a necesitar montarlo en un USB, de forma que la computadora entienda que es un "disco" desde el cual instalar el sistema operativo. En este tutorial vamos a usar un programa para esto llamado Balena Etcher, pero hay varias otras alternativas también. Si no te funciona el Balena, podés encontrar tutoriales con varios programas acá.
El proceso es simple:
- Abrimos el programa y seleccionamos "Flash from file"

- Seleccionamos la memoria objetivo (en este caso, el USB)

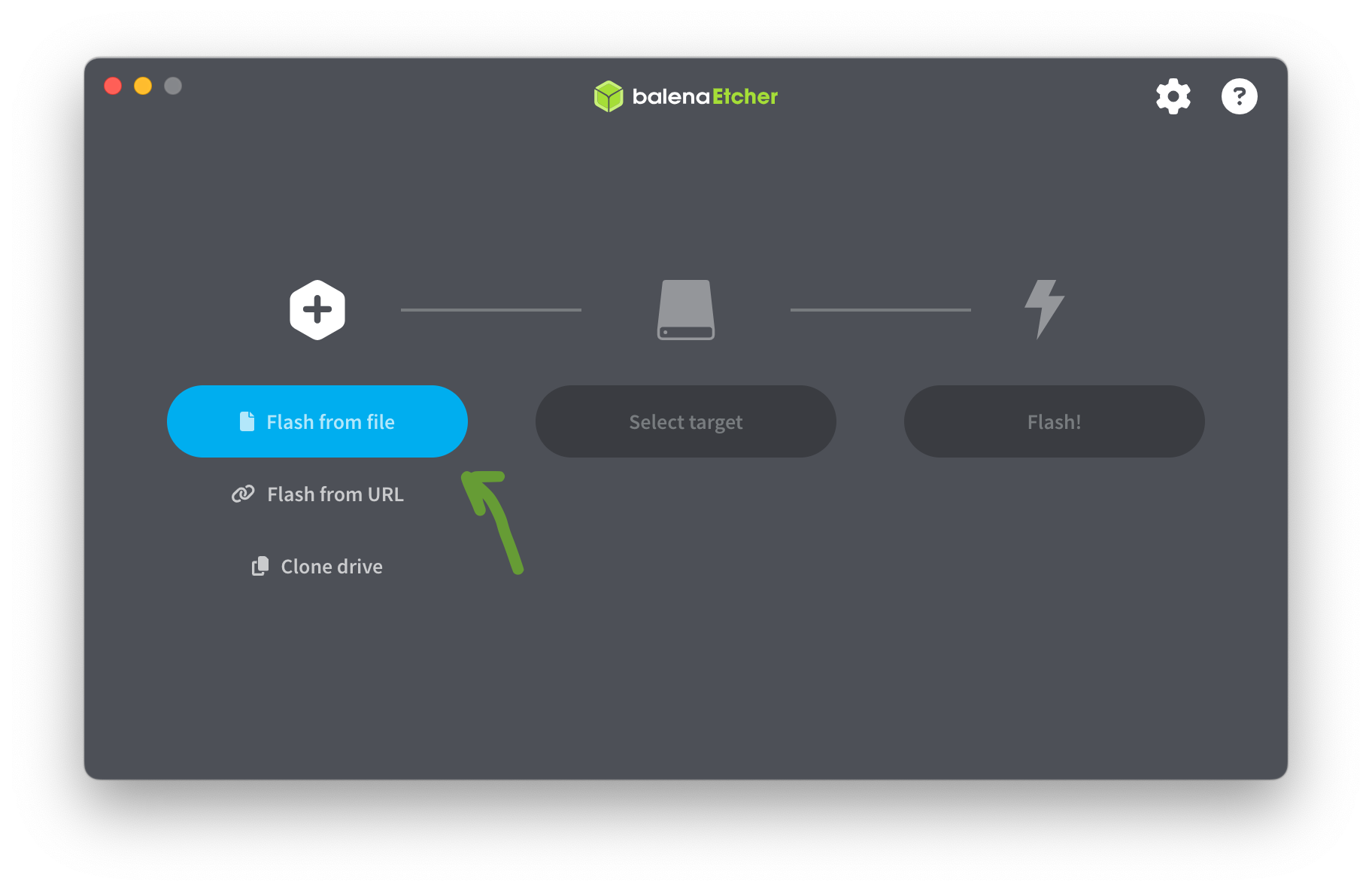
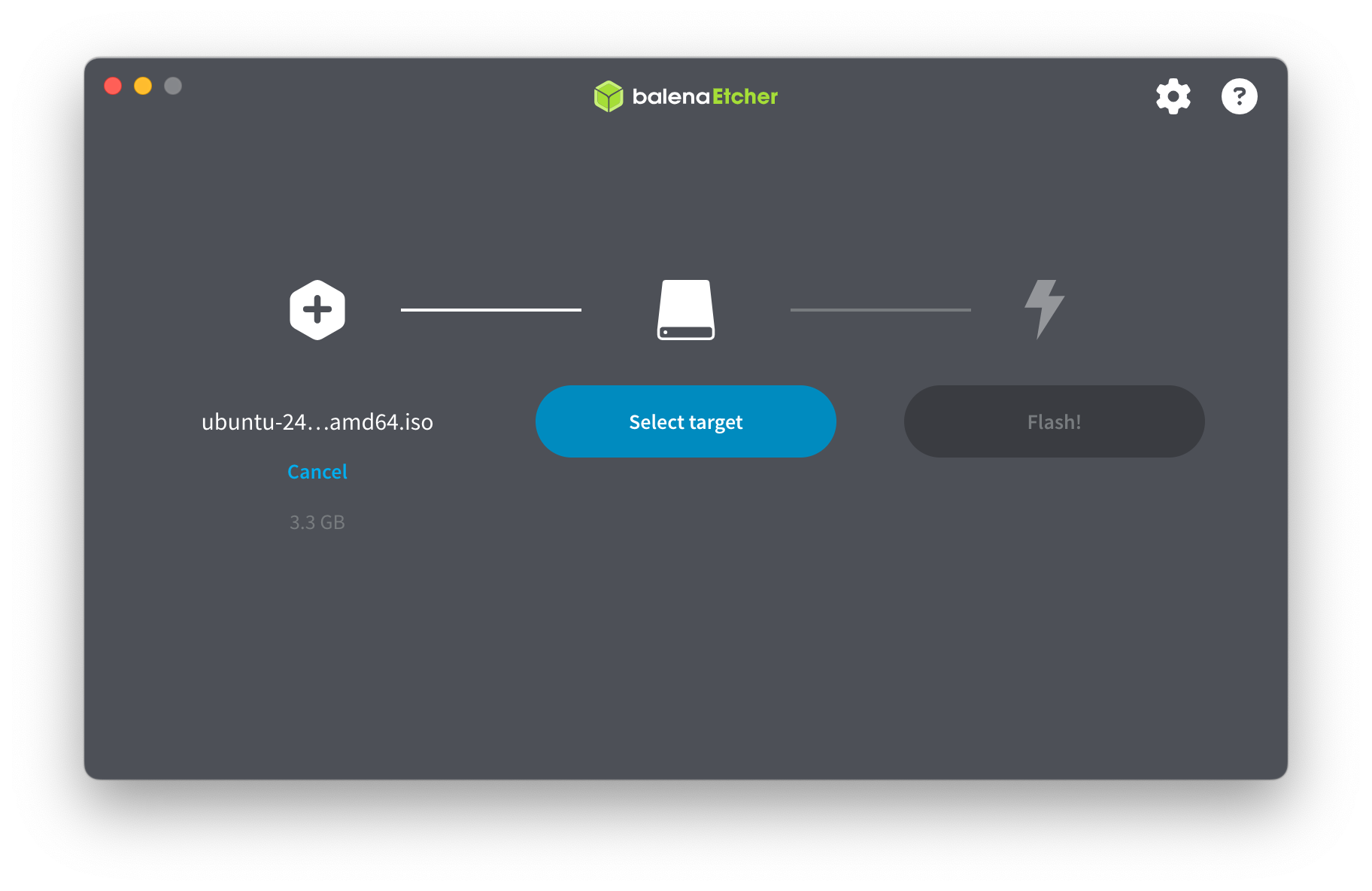
Prestá atención a que el tamaño del dispositivo que elijas sea en efecto el tamaño de la memoria que tenés, así te asegurás de quemar el .iso en el lugar correcto. Si por error eligieses el dispositivo donde está tu sistema operativo (tu disco rígido), podría traer muchos problemas! De todos modos, normalmente no están visibles estos dispositivos de entrada. Pero tené cuidado igual por las dudas.
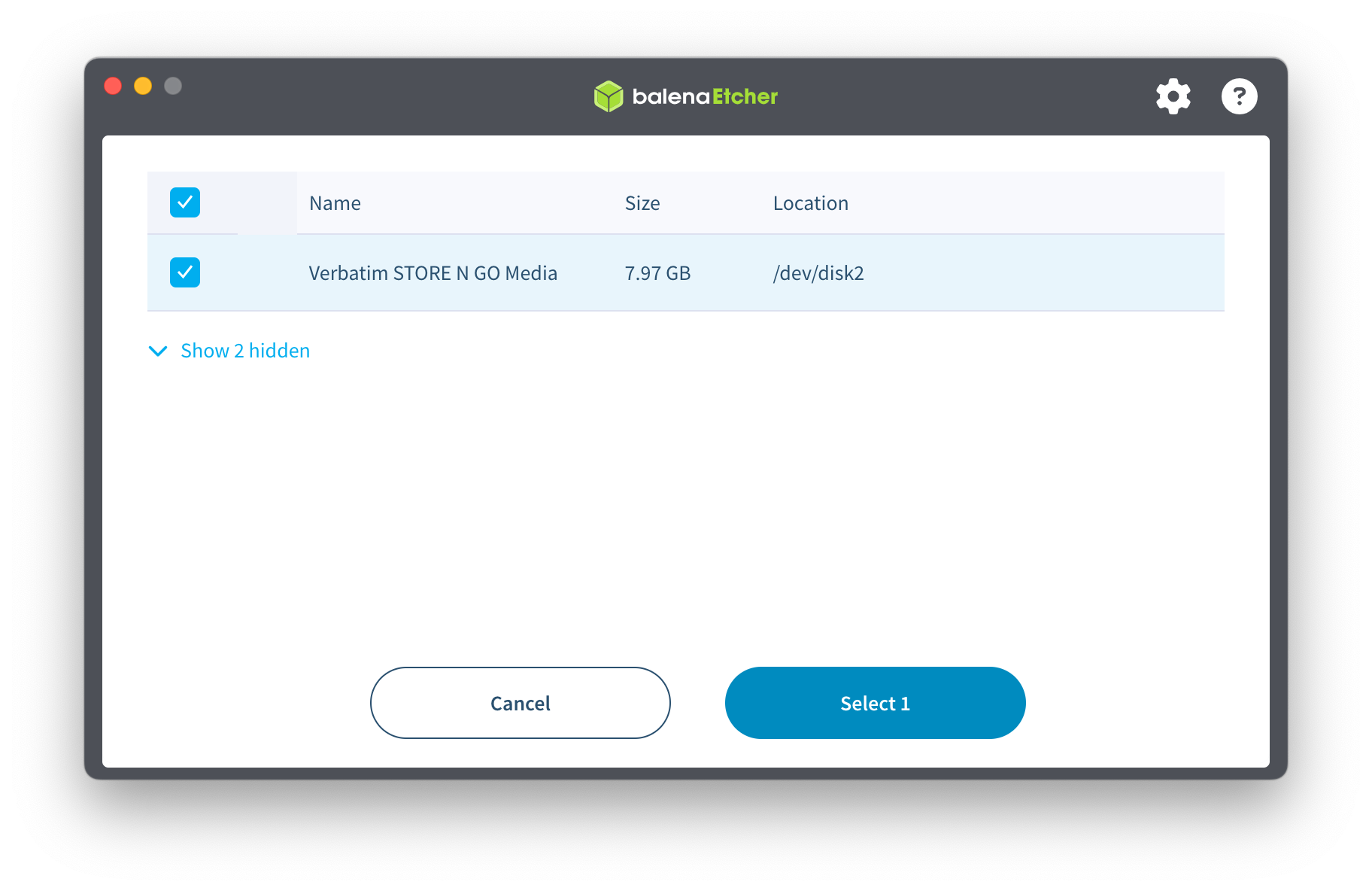 3. Seleccionamos
3. Seleccionamos Flash! y esperamos a que termine.
Una vez terminado, ya tenemos nuestro dispositivo USB listo para instalar linux.
Instalar Linux en la computadora
Preparación
Para hacer esto, vamos a necesitar hacer un par de cosas antes de arrancar, idealmente ambas con la compu apagada:
- Enchufar el USB a la computadora
- Enchufar la computadora a la red. Si bien se puede hacer a través de wi-fi, es mucho más fácil y rápido tener la compu enchufada a nuestro router.
Para el segundo ítem, fijate que tu router seguro tiene un par de enchufes para cables de LAN numerados (pueden ser sólo los números, tipo 1, 2, 3, 4, o pueden estar etiquetados como "Lan 1, Lan 2", etc, o "Local 1, Local 2"). Con enchufar el cable a cualquiera de esos puertos estás.
Instalación - Acceder al BIOS
Lo primero que vamos a tener que hacer es acceder al BIOS de la computadora. Este es como un "mini-sistema operativo" que todas las computadoras tienen, pensado específicamente para poder hacer cosas "por debajo" del sistema operativo que usamos siempre, como, por ejemplo, instalar otros sistemas operativos a la computadora. Para acceder al BIOS, por lo general, es necesario apretar una tecla en un momento apenas después de iniciar la computadora. Muchas veces la computadora tiene algún texto cuando aparece el logo de la marca que dice "Acceder al BIOS" o "Setup" o cosas por el estilo, y pide presionar alguna tecla (por lo general una de las "F", como "F2" que es de las más comunes, a veces "Esc" también puede ser). Si no encontrás este cartel, te recomiendo googlear el modelo de tu computadora en algo del estilo "How do I access the BIOS in <modelo de computadora>". Como teclas básicas para probar, te recomiendo F2, Esc, y F12, en ese orden. Por otro lado, como la ventana de tiempo para apretarlas es muy específica, recomiendo que las presiones repetidamente:
Instalación - cambiar el orden de prioridad de booteo
A la hora de iniciar la computadora (lo cual también se suele llamar "bootear", o "to boot" en inglés), el BIOS busca una instalación de algún sistema operativo para iniciar. Normalmente, esto lo hace primero buscando en el disco rígido, y si no encuentra ningún sistema operativo va viendo si hay algún dispositivo externo que tenga una instalación, como un pendrive o un CD. Para instalar el nuevo sistema operativo, vamos a tener que, desde el BIOS, poner como primer lugar a buscar el sistema operativo a los puertos USB, así detecta nuestro pendrive con el Live USB antes de la instalación que ya tenemos en el disco duro.
Para hacer esto, vamos a tener que buscar en el BIOS de nuestra computadora una sección que suele ser llamada "Boot Sequence", o "Boot Setup", o algo por el estilo. Abajo incluyo un video, pero es importante acá tener en cuenta que los BIOS suelen tener pequeñas diferencias en sus nombres, así que vas a tener que buscar por tu cuenta la sección que señala de dónde "bootea" la computadora.
Instalación - Instalar Linux
Una vez que cambiamos el orden de prioridad de booteo, si apagamos y encendemos la computadora con el USB conectado, va a pasar directamente (después de mostrarnos varios mensajes del proceso de arranque) a un menú de selección de qué "sistema operativo" queremos lanzar:
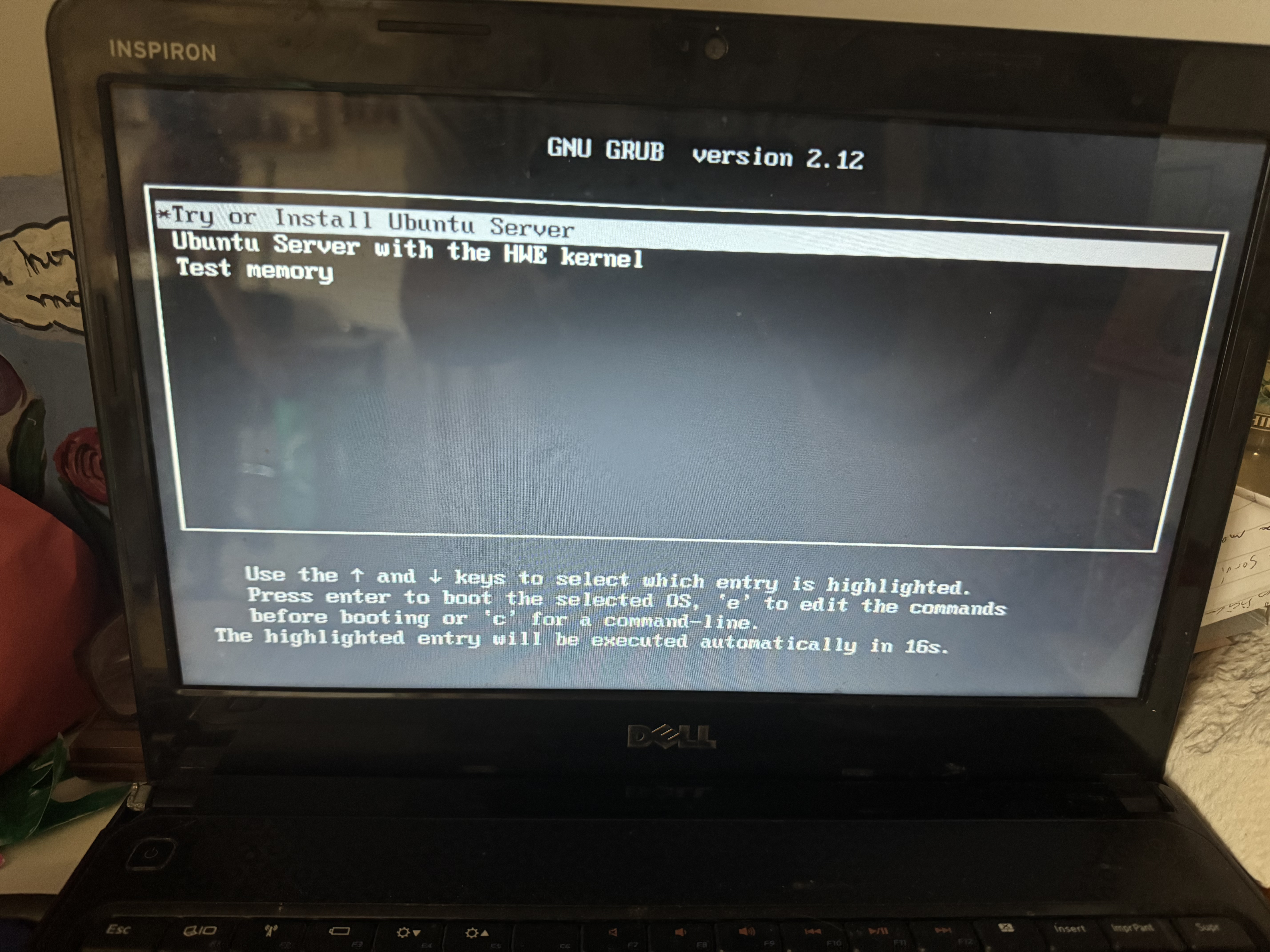
De ahí, seleccionamos con Enter la opción de instalar Ubuntu, lo cual nos lleva directamente a la primera pantalla de instalación de Ubuntu (luego de un poco de texto de mensajes de inicio):
De ahora en más, es sólo seguir los pasos de la instalación, sin embargo, un par de consideraciones importantes. Luego de elegir el tipo de teclado, nos va a ofrecer instalar Ubuntu Server o Ubuntu Server(minimized). Dejamos esto como está, pero nos importa la opción de más abajo: Search for third-party drivers. Ya que no sabemos de entrada si nuestra computadora tiene componentes de hardware que son "propietarios", es decir, cuyos drivers no son de código abierto, nos conviene marcar esta opción por las dudas.
La siguiente consideración importante llega en la sección de Network Configuration. Aquí vamos a querer hacer que nuestra computadora pida una IP estática a nuestra red. Si no, cada vez que la reiniciemos va a cambiar su dirección,y esto podría complicarnos las cosas. Para hacer esto seleccionamos los siguientes menúes:
Una vez nos encontramos en el formulario, los datos son los siguientes:
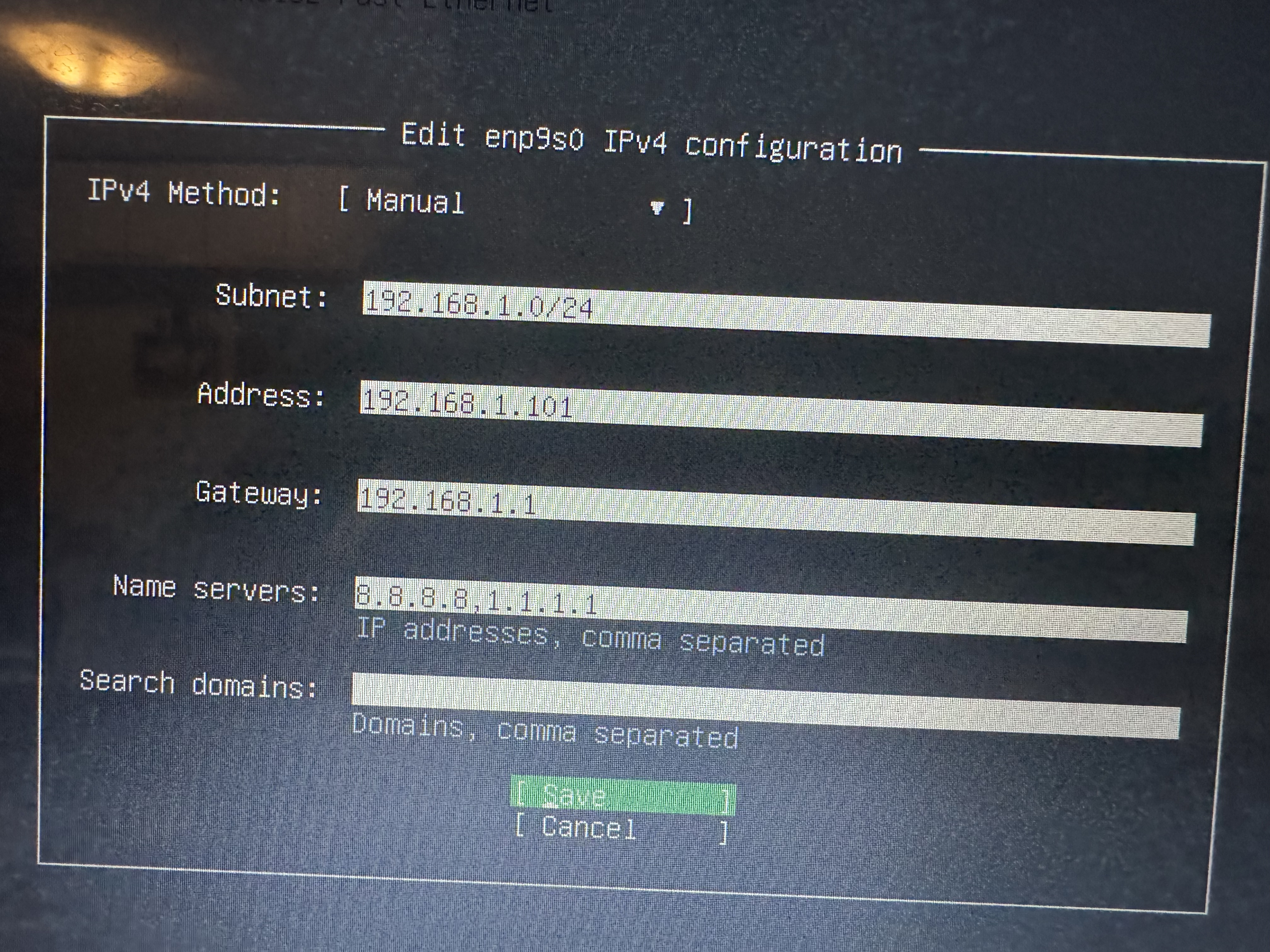
Tené cuidado, los datos pueden variar dependiendo de cómo está configurada tu red
Para poder ingresar bien tus datos, lo ideal sería que averigües la IP de tu router. Una vez que la tenés, esencialmente, la configuración sería la siguiente, pensándola por ejemplo con una IP de router de 10.0.2.1:
- Subnet: 10.0.2.0/24 (fijate que cambié el último dígito por un 0 y agregué el "/24")
- Address: 10.0.2.x (en lugar de x, poné el número de IP que vas a querer usar para acceder al servidor)
- Gateway: 10.0.2.1 (la IP del router)
- Nameservers: 8.8.8.8,1.1.1.1 (esto lo dejamos igual)
Luego, cuando nos pregunta si queremos usar un proxy, lo dejamos en blanco (a menos que sepas qué es esto y quieras usarlo, claro).
La siguiente pantalla también es una que tenemos que dejar como está si no sabemos del tema:
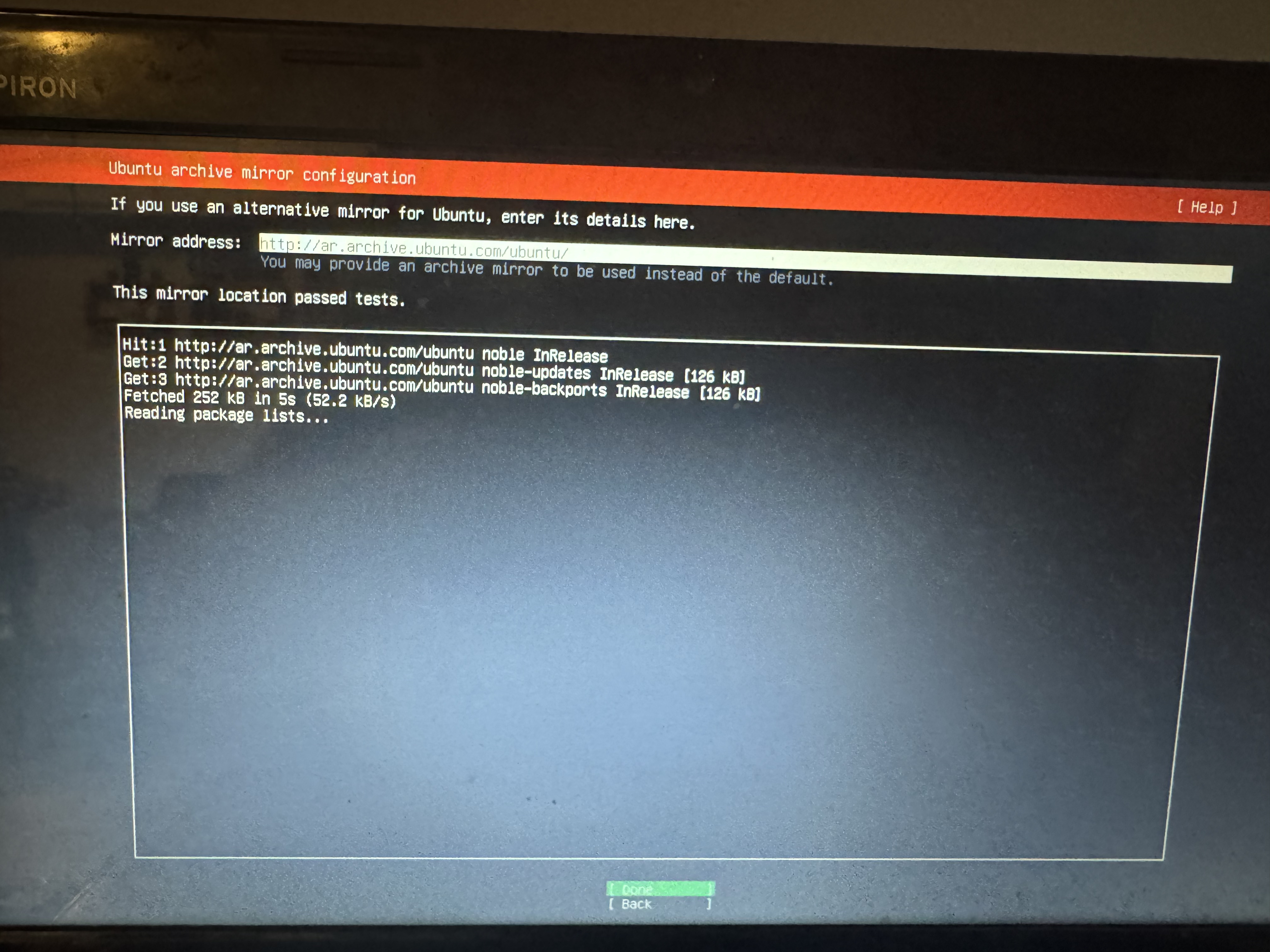
En este caso, tenemos que esperar a que tengamos el mensaje que figura en la imagen de This mirror location passed tests.(que, obviamente, no va a estar disponible cuando recién lleguemos a la pantalla.
En la siguiente pantalla, nos vamos a cerciorar de que estemos instalando el LVM (Live Volume Manager). Esta aplicación ahora mismo no la vamos a usar, pero si en el futuro queremos agregar más memoria a nuestro servidor (usando, por ejemplo, un disco rígido externo), nos va a venir bien.
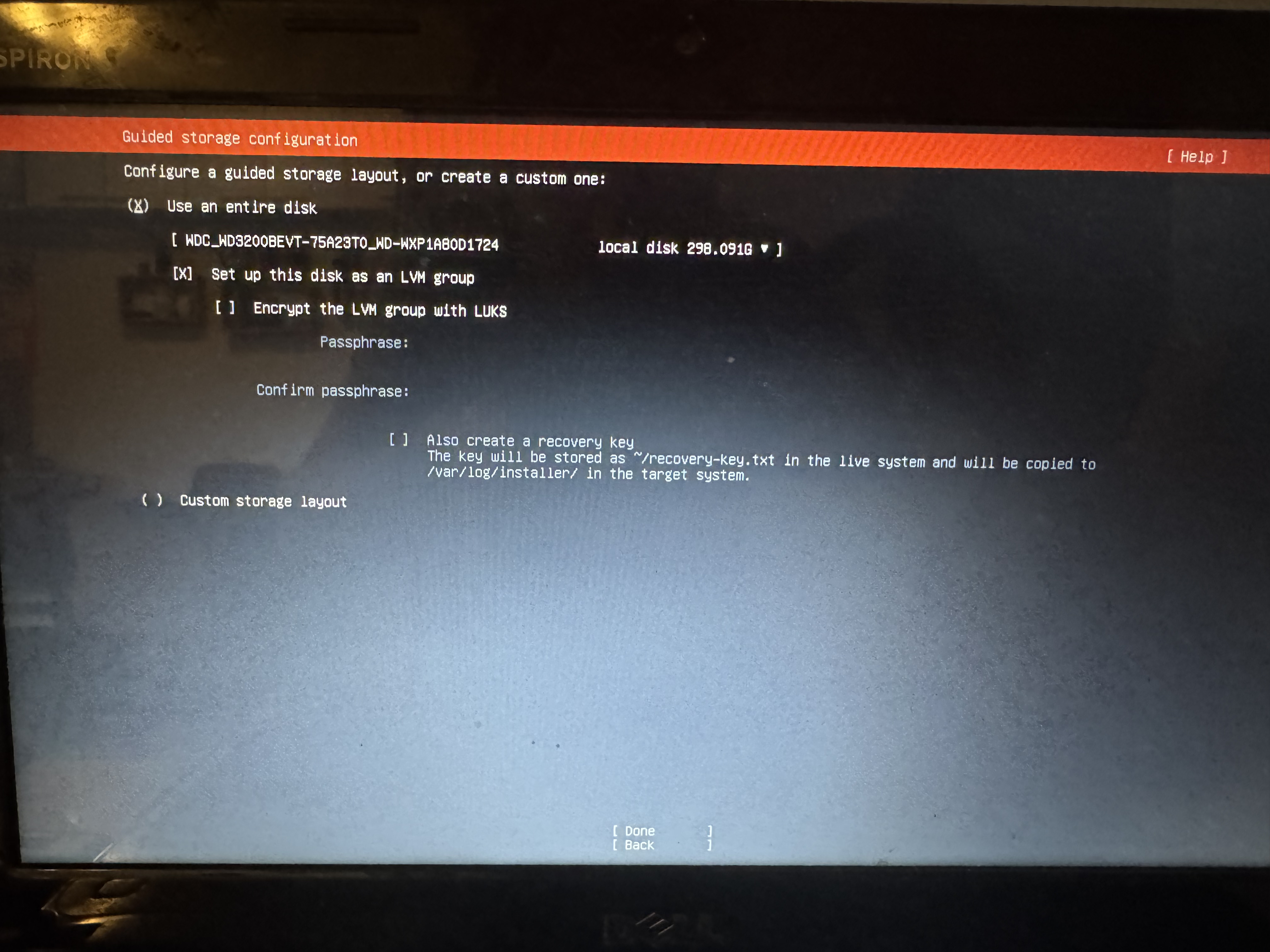
En la siguiente pantalla, vamos a poder configurar cuánto espacio de nuestra computadora le dedicamos a cada partición (segmento del disco rígido); por ahora podemos dejar las opciones como están y seguir.
El siguiente lugar, la sección titulada SSH configuration, es muy importante
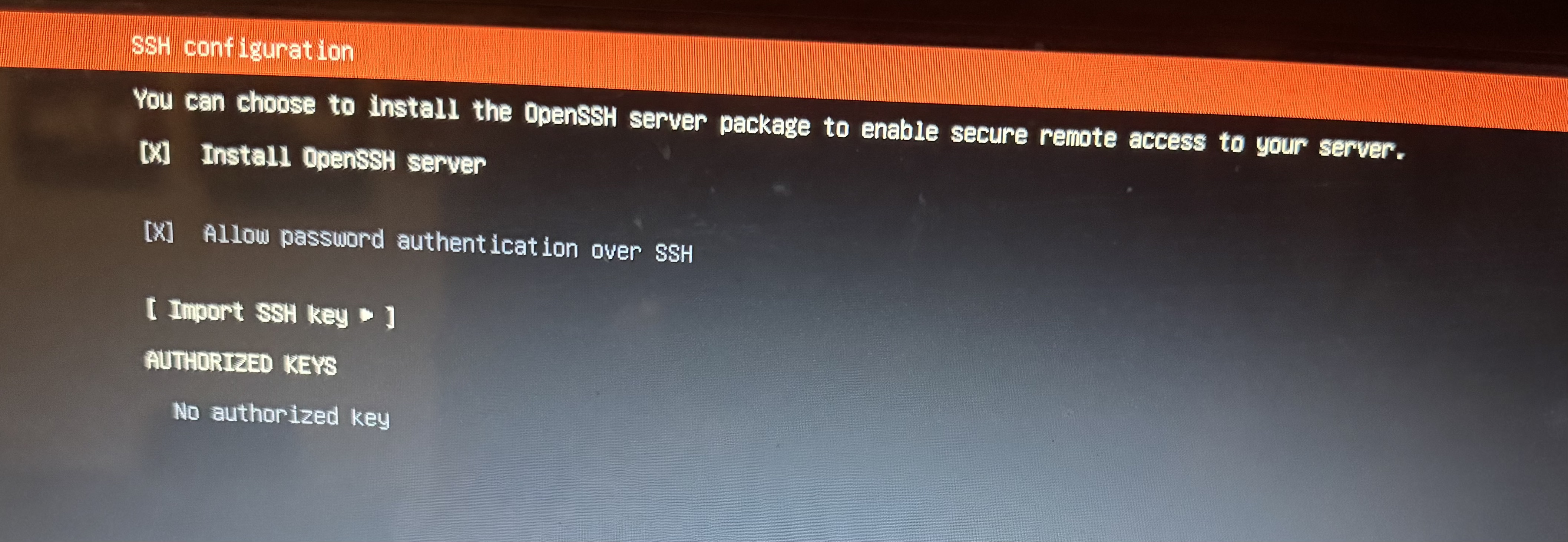
Luego de esta pantalla, vamos a tener un par más, incluyendo una en la que nos va a ofrecer instalar "snaps", un tipo de paquete ("paquetes" básicamente son apps) de Ubuntu, pero no le vamos a dar bola y no vamos a instalar nada. Finalmente, llegamos a la pantalla de instalación, donde nos va a aparecer mucho texto al que esencialmente no le tenemos que prestar atención. La instalación puede tomar un rato, dependiendo de la compu, así que es un buen momento para hacerse un mate o poner a lavar la ropa.
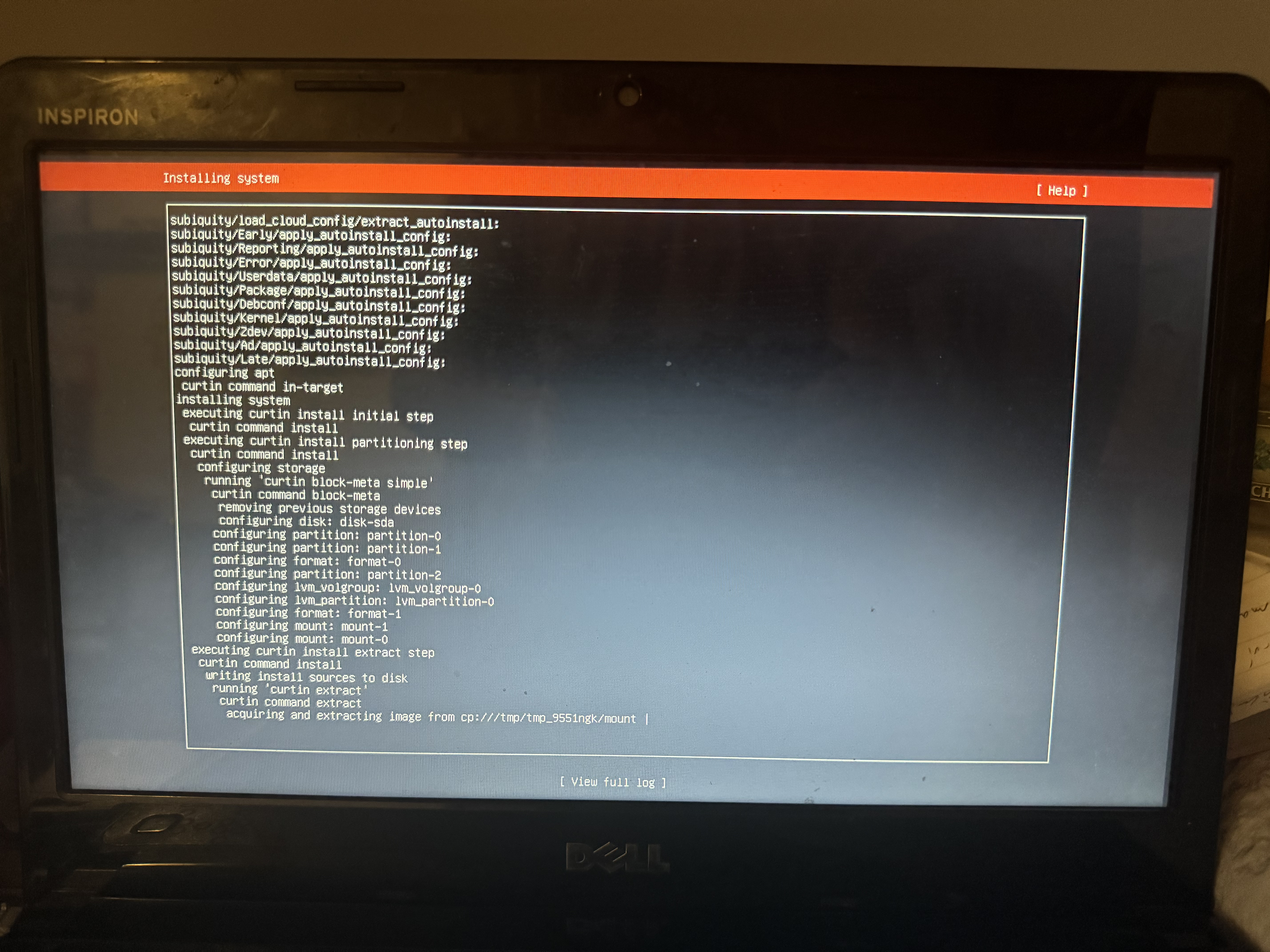
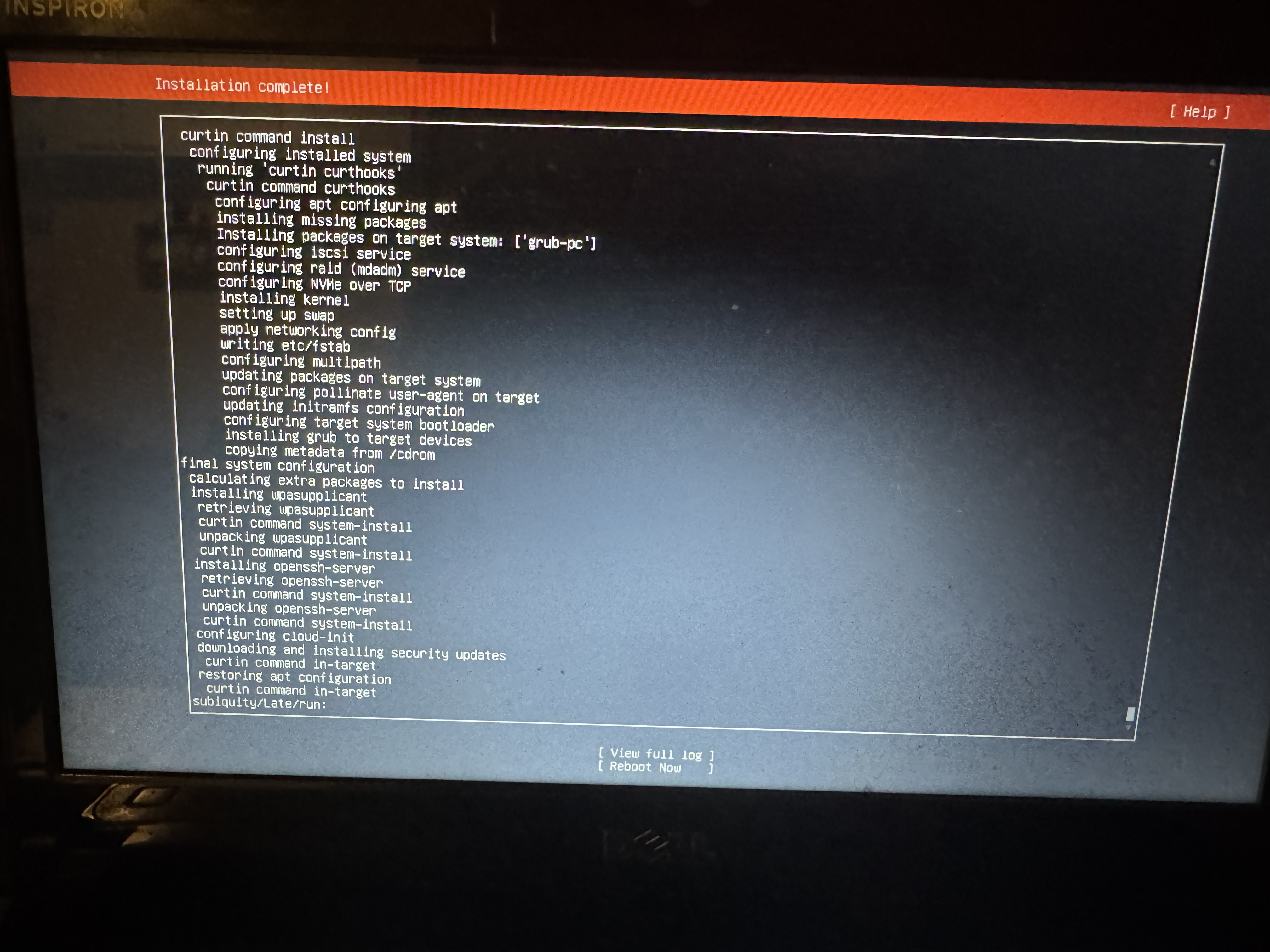
Una vez finalizada la instalación (nos va a figurar un mensaje del estilo "Instalation Complete" en la barra roja), vamos a tener la opción de reiniciar (reboot) la computadora. Cuando lo hagamos, ya vamos a haber terminado la instalación! Al reiniciar, nos va a figurar un mensaje pidiéndonos que quitemos el USB desde el que instalamos el sistema operativo, y aprentemos Enter:
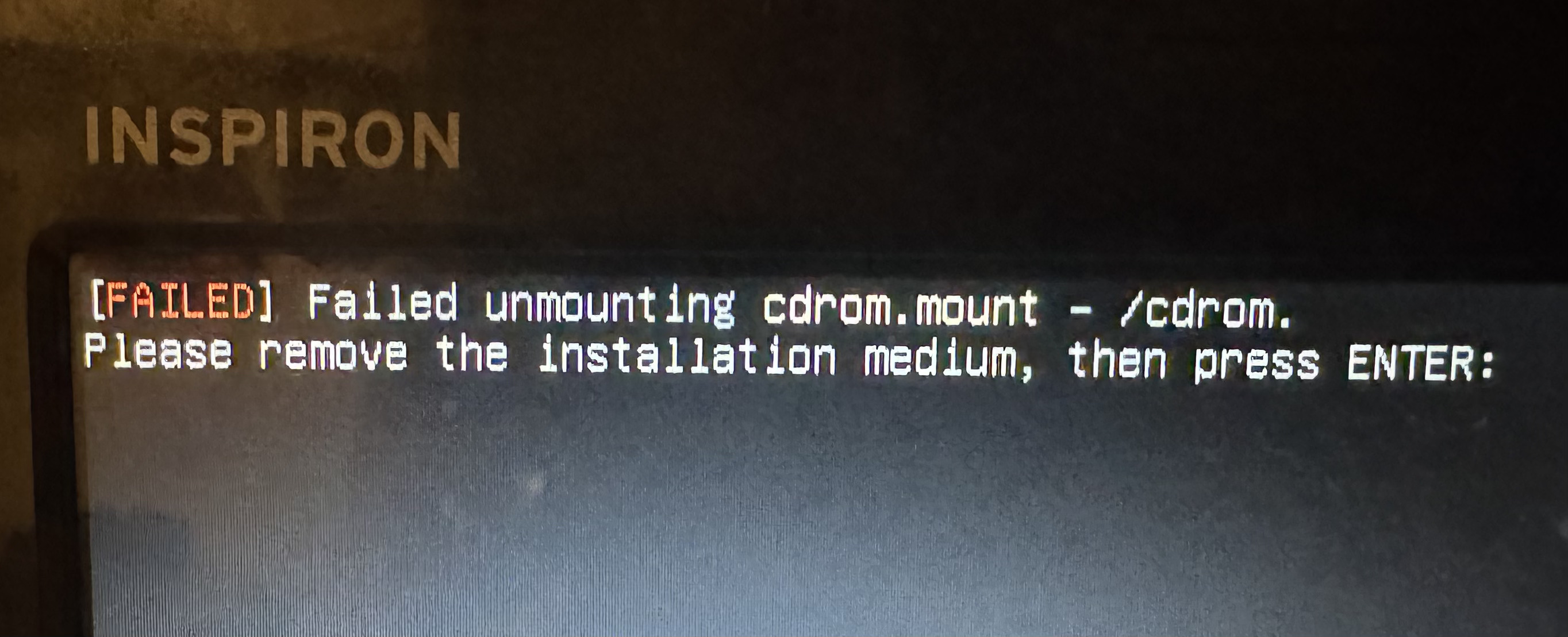
Y listo! El sistema se va a reiniciar con Ubuntu. La primera vez que se inicie, nos va a aparecer mucho texto, y va a parecer que no inició; es cuestión de apretar "Enter" nada más.
Ya estamos! Lo que sigue, ahora, sería ajustar un par de cosas en caso de ser una notebook, y luego, para la mayoría de los proyectos de esta página, al menos, instalar docker y docker compose.
Felicitaciones, ahora sos un ñoñx de Linux! De ahora en más, podés guardar tu servidor en donde sea que lo vayas a tener guardado (si es una laptop, fijate de entrar al link de arriba porque cuando la cierres probablemente se suspenda y no puedas acceder desde afuera para usarla); todo el trabajo que hagamos en adelante lo podemos hacer a través de ssh. También, para una interfaz gráfica más cómoda para alguna gente, podemos instalar cockpit. De todos modos, aprender a manejar ssh sigue siendo algo importante para manejar tu servidor.
Es importante que guardes tu server en algún lugar con espacio o, idealmente, fresco. Si tiene algún tipo de ventilación es ideal, ya que las computadoras pueden levantar temperatura y si el entorno no ventila un poco, puede traer problemas. Existen "cajas" para guardar servidores con venitladores, pero con guardarlo en algún espacio abierto o en algún estante grande está bien.
Instalar python
Afortunadamente, la mayoría de los distros de linux incluyen una versión de Python ya instalada. Podemos chequear si tenemos python usando el siguiente comando en la terminal: which python3
Si python ya está instalado, obtendremos un resultado del estilo:

Es importante usar el comando python3 y no python a la hora de revisar esto.
Además de python3, vamos a necesitar pip3, el gestor de paquetes de python(esencialmente la manera de descargar e "instalar" programas de python). La instalación es similar: Primero revisamos si lo tenemos con which pip3. Si no obtenemos ningún mensaje en consecuencia de la índole de /usr/bin/pip3, ejecutamos sudo apt update y sudo apt install python3-pip.
Instalar docker y docker compose
Esta sección es, esencialmente, una versión condensada de la [documentación oficial de Docker](https://docs.docker.com/engine/install/ubuntu/) respecto a la instalación del mismo en Ubuntu. Si querés, podés seguir las instrucciones oficiales de ahí, que van a ser más detalladas y completas.
Para instalar docker, lo primero que vamos a tener que hacer va a ser verificar que no tengamos una versión de docker pre-instalada en nuestra distribución de Linux, ya que puede traer problemas de compatibilidad en el futuro. Para eso, debemos correr el siguiente comando:
sudo apt remove $(dpkg --get-selections docker.io docker-compose docker-compose-v2 docker-doc podman-docker containerd runc | cut -f1)
(Vale aclarar que es posible que apt, el programa que corremos con ese comando, nos indique que no desinstaló nada ya que no había una versión previa instalada)
Una vez hecho esto, vamos a instalar docker usando apt también, así cada vez que actualizamos nuestros paquetes se actualiza a su vez docker. Para esto, primero vamos a tener que agregar el repositorio de docker a apt, copiando todos los siguientes comandos juntos, pegándolos en la consola, y apretando Enter:
# Agrega la llave GPG oficial de Docker:
sudo apt update
sudo apt install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Agrega el repositorio a las fuentes de apt:
sudo tee /etc/apt/sources.list.d/docker.sources <<EOF
Types: deb
URIs: https://download.docker.com/linux/ubuntu
Suites: $(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}")
Components: stable
Signed-By: /etc/apt/keyrings/docker.asc
EOF
sudo apt update
Luego, para finalmente instalar docker, debemos ejecutar el siguiente comando:
sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Una vez corrido esto, docker debería estar instalado. Para verificar que esté corriendo (cosa que debería pasar automáticamente), vamos a correr el siguiente comando:
sudo systemctl status docker
Si figura como active (running), significa que ya está corriendo:
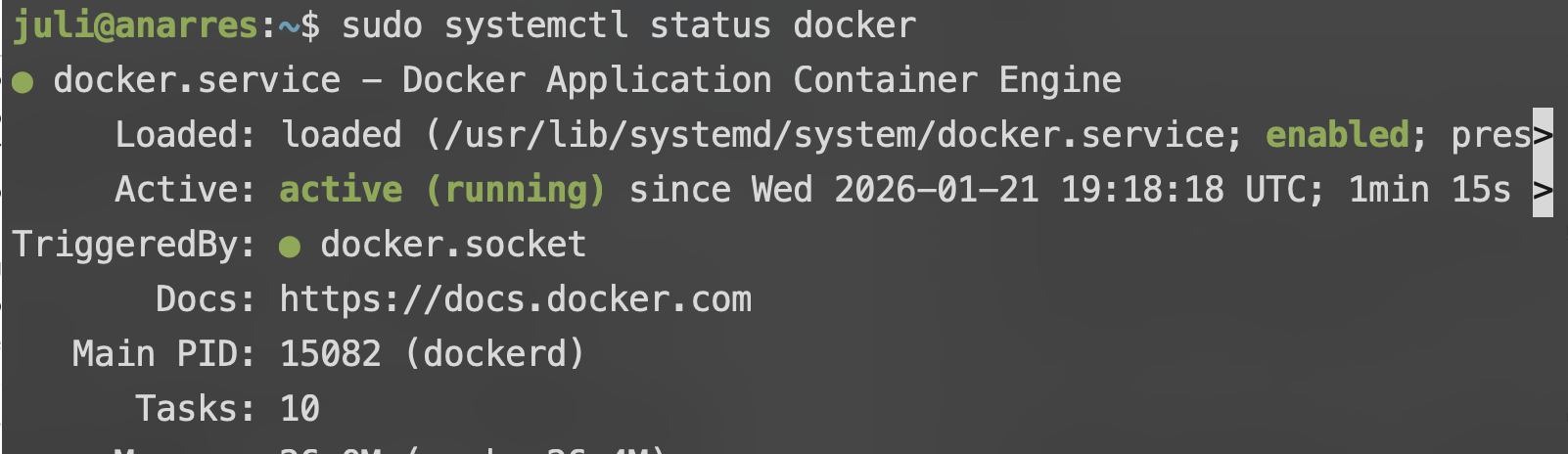
Para salir de esta "pantalla" de información, podés apretar q.
Si no figura como active(running), tenemos que iniciarlo manualmente, escribiendo:
sudo systemctl start docker
Por último, vamos a verificar que la instalación funcionó bien corriendo:
sudo docker run hello-world
Debería mostrarnos algo por el estilo:
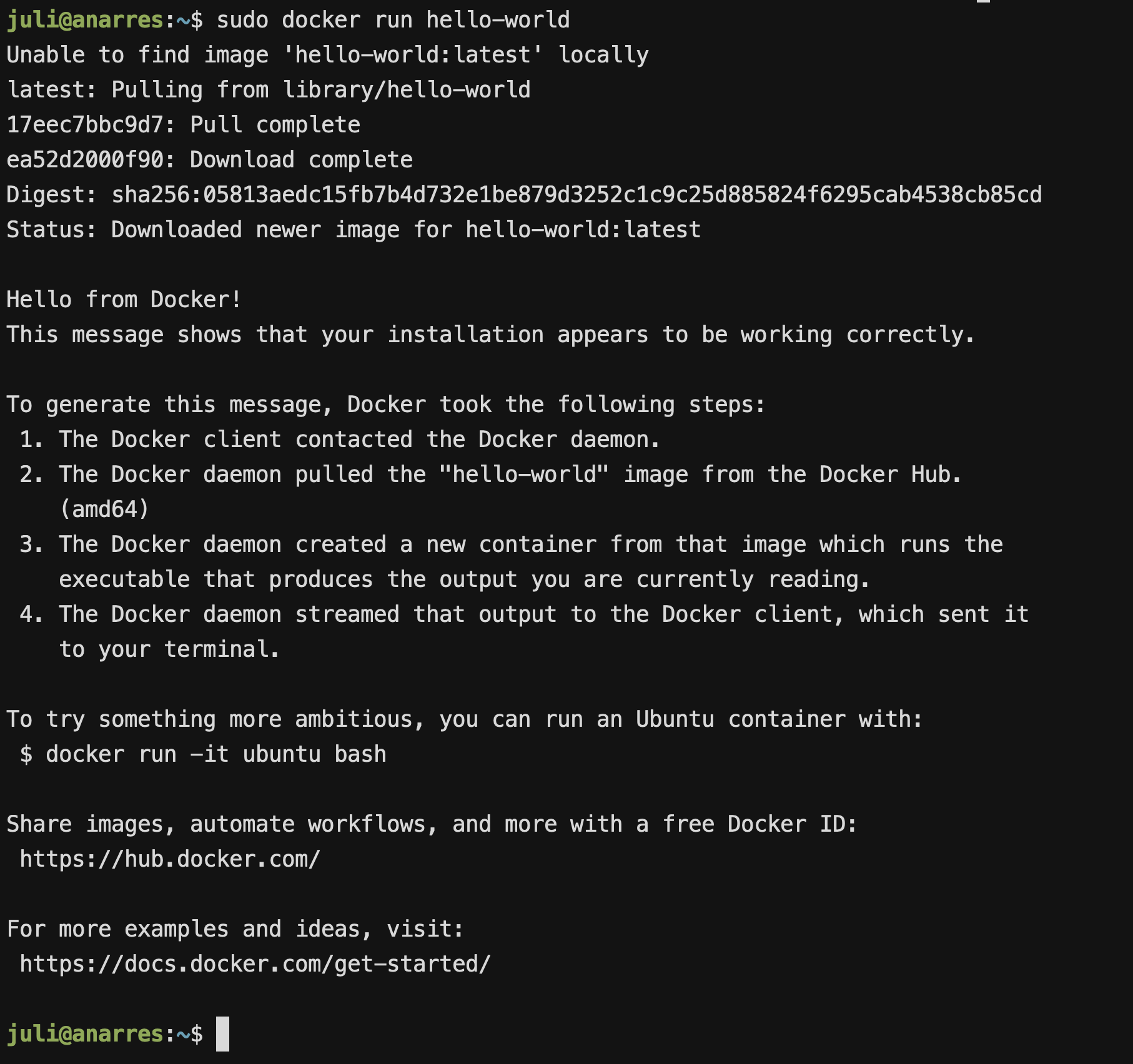
Y listo! Si esto te funcionó así, significa que ya tenés instalado y corriendo docker. Ya podés pasar al siguiente paso de la guía!
El Reverse Proxy
Qué es un reverse proxy?
Sinopsis
En el artículo sobre el router hablamos sobre cómo, cuando una computadora de afuera quiere conectarse con nuestro servidor, el router se encarga de "dirigir" la compu de afuera a nuestro server en la red local. Si nuestro server sólo proporciona un servicio, esto es ideal: Alguien se conecta, por ejemplo, a https://paginapirincho.com y pirincho, que en su server tiene un netflix privado, "sirve" ese contenido.
Pero qué pasa si, por ejemplo, la misma computadora sirve un netflix privado y, además un blog de cocina? https://peliculas.paginapirincho.com debería llevarnos al netflix, y https://blog.paginapirincho.com al blog. Pero si están en la misma computadora, el router "dirige" pedidos de ambas páginas hacia la misma computadora. Cómo sabe la computadora qué servicio servir? Para esto existen los reverse proxies.
Paso a paso
Un reverse proxy es un programa que ponemos al frente de nuestra computadora, que recibe todos los pedidos que vayan a esa compu, y se encarga de "dirigirlos", igual que el router, pero a nivel interno de la computadora. Además de esto, el reverse proxy cumple varias funciones de seguridad para nuestro server y para la gente que lo usa, y también nos resuelve algunas complejidades vinculadas con el problema (que quizás ya notaron, o quizás no) de no poder acceder cómodamente a páginas que no tengan "https" en lugar de "http" en la dirección (para más data, googlea "TLS" o "SSL", pero te advierto que es un tema complejo).
El esquema terminaría siendo algo así:

Lo que pasaría, entonces:
- Computadora externa se conecta a nuestra IP pública pidiéndo la página
https://blog.paginapirincho.com. - Nuestro router recibe la conexión externa (en el puerto predeterminado que usamos para conexiones de http o https, las conexiones que usan nuestros navegadores de internet, que son el 80 y el 443) y la redirige a la dirección interna de nuestro server, pasándo el pedido de la página
https://blog.paginapirincho.com. - Dentro de nuestro servidor, nuestro reverse proxy recibe ese pedido en el puerto predeterminado (80 o 443, ambos se usan, y nuestro reverse proxy "presta atención" o "escucha" a ambos puertos), busca en su configuración las instrucciones de qué hacer con esa página, encuentra que hay que redirigir hacia el puerto 3000 y lo hace. Le pide al programa del blog que le dé el blog, el programa se lo da al reverse proxy, que se lo da al router, que finalmente le llega a la computadora, externa.
Guía: Instalar y configurar mi reverse proxy
Qué es Caddy?
Caddy es una aplicación de servidor de código abierto. Un programa "servidor" es esencialmente eso: Un programa que, cuando le hablan, sirve contenido. En este caso, lo vamos a utilizar para que sirva contenido actuando como "reverse proxy": No le vamos a dar el contenido directamente, sino que le vamos a pedir que "redirija" las conexiones a las aplicaciones que corramos en nuestro server y obtenga el contenido desde ahí.
Para utilizar caddy, es muy recomendable que hayas ya configurado un dominio para tus servicios
Instalación
Como en todos los tutoriales de esta guía, la instalación va a ser en sistemas Linux; específicamente, en sistemas de tipo "debian", como Debian, Ubuntu, o Linux Mint
Instalar Caddy, por suerte, es muy fácil (por lo menos, lo es en Linux ;) ). Simplemente corré los siguientes comandos en una consola o terminal:sudo apt update
sudo apt install caddy
Recordá que, cuando uses comandos con [sudo](https://wiki.cuquiweb.xyz/link/14#bkmrk-sudo), el sistema operativo va a pedirte la contraseña, ya que estás instalando programas como administradorx.
En caso de que no funcione, las instrucciones oficiales indican estos comandos:
sudo apt install -y debian-keyring debian-archive-keyring apt-transport-https curl
curl -1sLf 'https://dl.cloudsmith.io/public/caddy/stable/gpg.key' | sudo gpg --dearmor -o /usr/share/keyrings/caddy-stable-archive-keyring.gpg
curl -1sLf 'https://dl.cloudsmith.io/public/caddy/stable/debian.deb.txt' | sudo tee /etc/apt/sources.list.d/caddy-stable.list
chmod o+r /usr/share/keyrings/caddy-stable-archive-keyring.gpg
chmod o+r /etc/apt/sources.list.d/caddy-stable.list
sudo apt update
sudo apt install caddy
Una vez que lo instalaste, fijate si está corriendo ya con el comando systemctl status caddy. Esto debería abrirte un cuadro similar a esto:
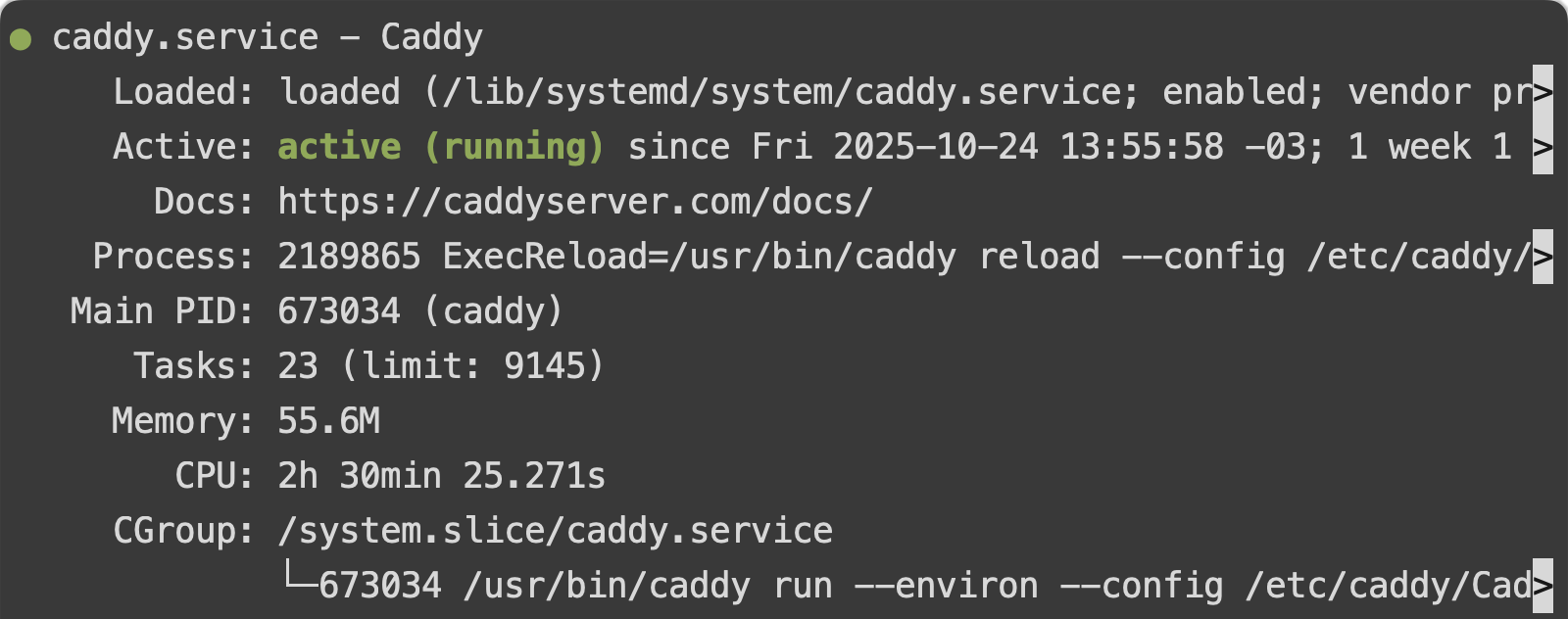
Para volver a la consola, probá apretar q
Si te indica que no está activo, lo podés poner a andar escribiendo sudo systemctl start caddy (notá que este comando lleva sudo).
Configuración
Dejo dos maneras de configurar caddy. La primera es la más simple. Si sólo vas a tener un servicio o dos corriendo en tu servidor, esta te puede alcanzar. Sin embargo, a medida que se agreguen servicios, puede llegar a complicar un poco la lectura y modificación de la configuración. Para esto, vamos a usar una segunda propuesta, un poco más avanzada y que requiere un par de pasos más, pero más estructurada y fácil de leer y modificar.
Puntos en común
El archivo Caddyfile
Si bien vamos a ver dos formas de armar nuestra configuración de caddy, ambas comparten un par de principios. El primero es que caddy guarda su configuración en el directorio /etc/caddy/, en un archivo llamado Caddyfile. En este archivo vamos a poder encontrar todas las "directivas" para el programa: Es decir, la "tablita" que el programa lee para ver qué hacer con cada dirección que reciba. Si no figura acá, el programa no va a hacer nada, y no va a "servir" ningún contenido.
Para abrir el archivo, primero debemos movernos al directorio de la configuración con el comando cd /etc/caddy (nótese la barra diagonal al comienzo de la dirección, esto es importante). De esta forma, todas las cosas que hagamos se van a llevar a cabo en este directorio.
Una vez en el directorio apropiado, vamos a abrir el Caddyfile con el comando sudo nano Caddyfile. Este comando nos va a abrir un editor de texto on el que vamos a poder editar el archivo. Ya que es un archivo del sistema, y no del usuario en específico, necesitamos utilizar sudo al comienzo del comando.
Cuando terminemos de editar el archivo, vamos a poder guardarlo con Ctrl+o (apretamos enter para confirmar que el nombre del archivo sigue siendo el mismo), y lo cerramos con Ctrl+x.
Aplicar cambios
Cada vez que actualicemos nuestro Caddyfile, nuestro archivo de configuración, para implementar sus cambios vamos a tener que escribir el comando sudo systemctl reload caddy. Si no nos dice nada, significa que se reinició bien. Si no, nos va a tirar un error. Es muy importante prestar atención a tener los archivos en el caddyfile "bien escritos"; si nos comemos algún símbolo, es muy posible que nos tire un error.
Ejemplo de Caddyfile
En un Caddyfile, unx escribe "bloques" de indicaciones para cada dominio y subdominio, por ejemplo:
blog.midominio.com {
<qué "sirvo" para este dominio
}
Observemos el formato: Primero va el dominio, un espacio, y luego, entre llaves {}, qué hacer con las conexiones a ese dominio.
Configuración básica
Para nuestra configuración básica, vamos a escribir un Caddyfile que directamente va a contener los bloques de cada dirección a la que queremos que se pueda conectar la gente de afuera. En este ejemplo, voy a escribir un archivo Caddyfile que contendría dos servicios: Un blog en el puerto 3000, y un "netflix privado" en el puerto 8096:
blog.midominio.com {
reverse_proxy localhost:3000
}
neflis.midominio.com {
reverse_proxy localhost:8096
}
Nótense dos cosas: La dirección "localhost" es una dirección que refiere a que el servicio se encuentra en la misma computadora, en otro puerto (ya que Caddy "escucha" en los puertos estándar de conexión de internet http, 80y 443). (Sí, esto significa que podemos hacer que un dominio x sea "redirigido" mediante reverse proxy a otra IP o dominio externos a nuestro server, pero esto es mucho más avanzado y probablemente no lo necesitemos nunca).
Por otro lado, los dos puntos indican qué puerto servimos: En el caso del "netflix", que corre "atendiendo" el puerto 8096, usamos localhost:8096. Esto funciona en un navegador también. Si ponemos https://undominio.com:8000, estamos indicando que nos queremos conectar al puerto 8000 de la computadora conectada a ese dominio. Cuando no aclaramos nada, por defecto "pide" el puerto 443 (y, a veces, el puerto 80).
Una vez escrito este archivo Caddyfile, podemos cargar la nueva configuración con sudo systemctl reload caddy.
Configuración avanzada
A medida que vayamos agregando nuevos servicios a nuestro servidor, este archivo inicial se puede llegar a hacer muy grande y difícil de navegar y leer. Además de esto, quizás queremos correr alguna de las otras directivas de Caddy, para varias cosas más avanzadas que hagamos, como logear, o correr algún tipo de protección como crowdsec.
Para "reconfigurar" nuestra configuración de Caddy, vamos a empezar por crear los directorios sites-available y sites-enabled. En sites-available vamos a ingresar la configuración de cada servicio de caddy, y los vamos a "conectar" con un link simbólico (algo así como un "acceso directo", un archivo que apunta a otro archivo) en la carpeta sites-enabled cuando queramos que esos sitios estén disponibles. De esta forma, si en algún momento queremos dejar de servir, por ejemplo, nuestro netflix privado, sólo tenemos que eliminar ese archivo en sites-enabled, sin borrar la configuración que teníamos armada. Cuando queramos volver a servirlo, sólo tenemos que crear el link de nuevo.
Para crear los directorios, vamos a usar los siguientes comandos:
cd /etc/caddy/ # Para movernos hacia la carpeta de la configuración
sudo mkdir sites-available
sudo mkdir sites-enabled # Crea ambos directorios
No es necesario copiar lo que viene después del `#`, incluyendo el propio símbolo: Representa comentarios que el "intérprete" de la consola va a ignorar. Si los escribís, no cambia nada.
Una vez creados, la estructura local del directorio /etc/caddy debería ser la siguiente: (en este ejemplo, usamos los mismos dos servicios que teníamos antes)
Caddyfile
sites-available/
|- blog.midominio.com <-- Bloque de config de blog
L- neflis.midominio.com <-- Bloque de config de neflis
sites-enabled/
|- blog.midominio.com <-- Link al archivo en sites-avail
L- neflis.midominio.com <-- Link
Los subdirectorios están indicados con una barra diagonal / al final del nombre. Si no tiene esta barra diagonal, es un archivo
Una vez creadas la carpetas, tenemos que tomar cada bloque de cada servicio y escribirlo en un archivo en el directorio sites-available. Por ejemplo, copiamos el bloque del blog, y lo copiamos en el archivo propio con el comando sudo nano sites-available/blog.midominio.com. Dentro del archivo quedaría:
blog.midominio.com {
reverse_proxy localhost:3000
}
Hacemos lo mismo con el archivo del "neflis". Ambos bloques los borramos del Caddyfile.
En el Caddyfile, le indicamos que "incluya" todas las "sub-configuraciones" que se encuentran en la carpeta sites-enabled. Nuestro archivo Caddyfile, en principio, quedaría únicamente así:
import sites-enabled/*
El * en la indicación significa "todo" lo que está en la carpeta sites-enabled
Por último, creamos los "accesos directos" dentro de la carpeta sites-enabled que apunten a las configuraciones individuales. En este ejemplo uso la configuración del blog:
sudo ln -s /etc/caddy/sites-available/blog.midominio.com /etc/sites-enabled/
(Nótese que uso "paths absolutos", que empiezan con una barra diagonal /).
Hacemos lo mismo con cada sitio que queremos que esté "activado".
Finalmente, refrescamos la nueva configuración con sudo systemctl reload caddy.
Nótese que, mientras trabajamos en la carpeta /etc/caddy, necesitamos usar sudo cada vez que queremos escribir o modificar algo, pero no cada vez que queremos verlo. Esto es porque tenemos, como usuarios comunes no-administradores, permisos para ver pero no para modificar. Por esto con cd podemos "entrar" al directorio y ver sus contenidos, pero no podemos modificarlos sin usar sudo.
Configuraciones específicas de Notebooks
En esta página vamos a ver un par de ajustes que tenemos que hacer a nuestro server en caso de haberlo instalado en una Laptop (notebook, netbook, cualquier cosa del estilo). Esencialmente, tenemos que tener en cuenta dos cosas principales:
- Que no se suspenda la laptop cuando cerremos la pantalla.
- Que se apague la pantalla cuando la cerremos, también.
Cambiar comportamiento de cierre de pantalla
En linux, muchas de las configuraciones están en archivos de texto, a veces llamados archivos "config". Estos se suelen guardar en el directorio /etc/. En este caso, el que queremos editar se encuentra en /etc/systemd/login.conf.
Lo vamos a abrir con el editor nano, un editor simple que se encuentra en la mayoría de las distribuciones de Linux, con el siguiente comando:
sudo nano /etc/systemd/login.conf.

Este comando va a llevar sudo, es decir que lo vamos a ejecutar como administradores. Por esto mismo, nos va a pedir la contraseña antes de permitirnos seguir. Una vez adentro, vamos a movernos con las flechas del teclado hasta encontrar la línea #HandleLidSwitch=suspend. Le vamos a eliminar el #, que indica que es un "comentario", es decir que es una línea que no hace nada aún (la línea está para indicarnos cuál es la opción por defecto, si no escribimos nada), y vamos a cambiar el suspend por lock. Esto va a indicar que cuando cerremos la tapa, se va a "desloguear" y vamos a tener que ingresar nuevamente cuando la abramos, pero crucialmente no se va a suspender la computadora, por lo que vamos a poder loguearnos remotamente a través del ssh.
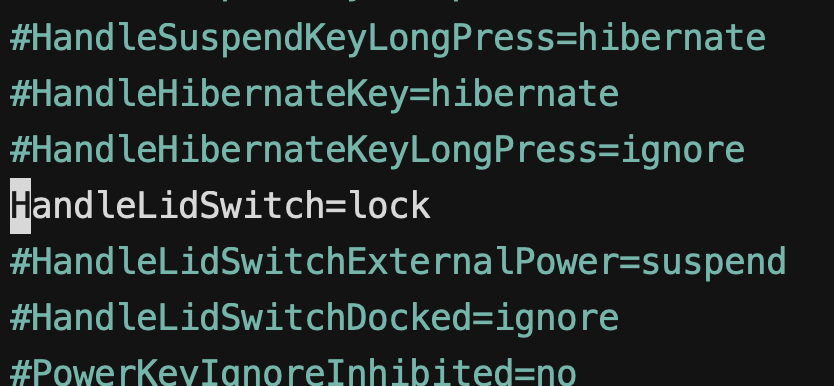
Para guardar los cambios, primero vamos a apretar Ctrl+O (de "Write Out"), tocamos Enter para guardar con el mismo nombre el archivo y luego Ctrl+Xpara salir.
Por último, vamos a necesitar reiniciar el servicio de systemd, al cual le acabamos de cambiar la configuración, con el comando:
sudo systemctl restart systemd-logind.service. Después de esto, la comptuadora no debería suspenderse cuando cerremos la tapa.
Configurar apagado de pantalla
Por lo general, la pantalla se debería apagar siguiendo los pasos de arriba, al menos unos segundos después de cerrar la pantalla. Sin embargo, si te das cuenta de que no es el caso, podés intentar lo siguiente:
Con nano, nuevamente, vamos a editar otro archivo:
sudo nano /etc/default/grub
Dentro de este archivo, vamos a buscar la línea que contiene GRUB_CMDLINE_LINUX_DEFAULT=, y a cambiarla por GRUB_CMDLINE_LINUX_DEFAULT=consoleblank=600.
Guardamos nuevamente con Ctrl+O, Enter, y salimos con Ctrl+X. De vuelta en la consola, escribimos el comando update-grub (es posible que nos pida que lo corramos como sudo, en cuyo caso corremos sudo update-grub e ingresamos nuestra contraseña), y luego reiniciamos la computadora con sudo reboot, y debería funcionar.
Usando el LVM
Usando el LVM (Logical Volume Manager)
Qué es el LVM?
En los tutoriales de esta página, y específicamente cuando instalamos Linux (Ubuntu), recomendamos instalarlo con el lvm ya instalado y funcionando (lo cual es lo que Ubuntu ofrece desde el vamos). Si lo hiciste de esta forma, quizás te encuentres con algo interesante: Sin importar el espacio con el que tu disco cuente, sólo vas a tener 100 GB disponibles si revisas el espacio libre:

Esto ocurre porque Ubuntu instaló el LVM, que es un gestor de "discos virtuales", e instaló el sistema operativo en un logical volume (dicho disco virtual, llamado un volumen lógico) con 100 GBs. En este disco vamos a instalar todos nuestros contenedores (programas) y demás, pero si nos manejamos de esta forma, podemos designar cuánto espacio vamos a querer dedicarle a la data de nuestros otros servicios, guardando la música de nuestro Spotify o las pelis y series de nuestro Netflix en otros logical volumes con espacio delimitado, por ejemplo 200 GBs para música y 500 para películas, etc.
El LVM nos permite incorporar varias unidades físicas (como podrían ser el disco rígido de la computadora y un disco rígido externo) en una sóla unidad lógica (llamada volume group), sin tener que preocuparnos nosotrxs por qué va a parar adónde en esos discos. Si querés más info sobre cómo funciona esto, la página de red hat tiene una buena descripción.
Usando el lvm
En principio, la instalación de linux ya va a tener el lvm instalado y configurado, con sus unidades fundamentales ya definidas: Un volume group (vg), que va a agrupar los volúmenes que creemos, y un logical volume (lv) dentro de ese vg, normalmente de 100 GBs. Por lo tanto, nos vamos a enfocar en tres procesos básicos:
- Crear un lv
- Modificar el tamaño de un lv
- Eliminar un lv
Crear un Logical Volume
Lo primero que tenemos que hacer para esto es averiguar cuánto espacio sin asignar tenemos en nuestro vg, ya que este es el que vamos a tener disponible para asignar a nuestro lv. Para esto, vamos a escribir:
sudo vgdisplay
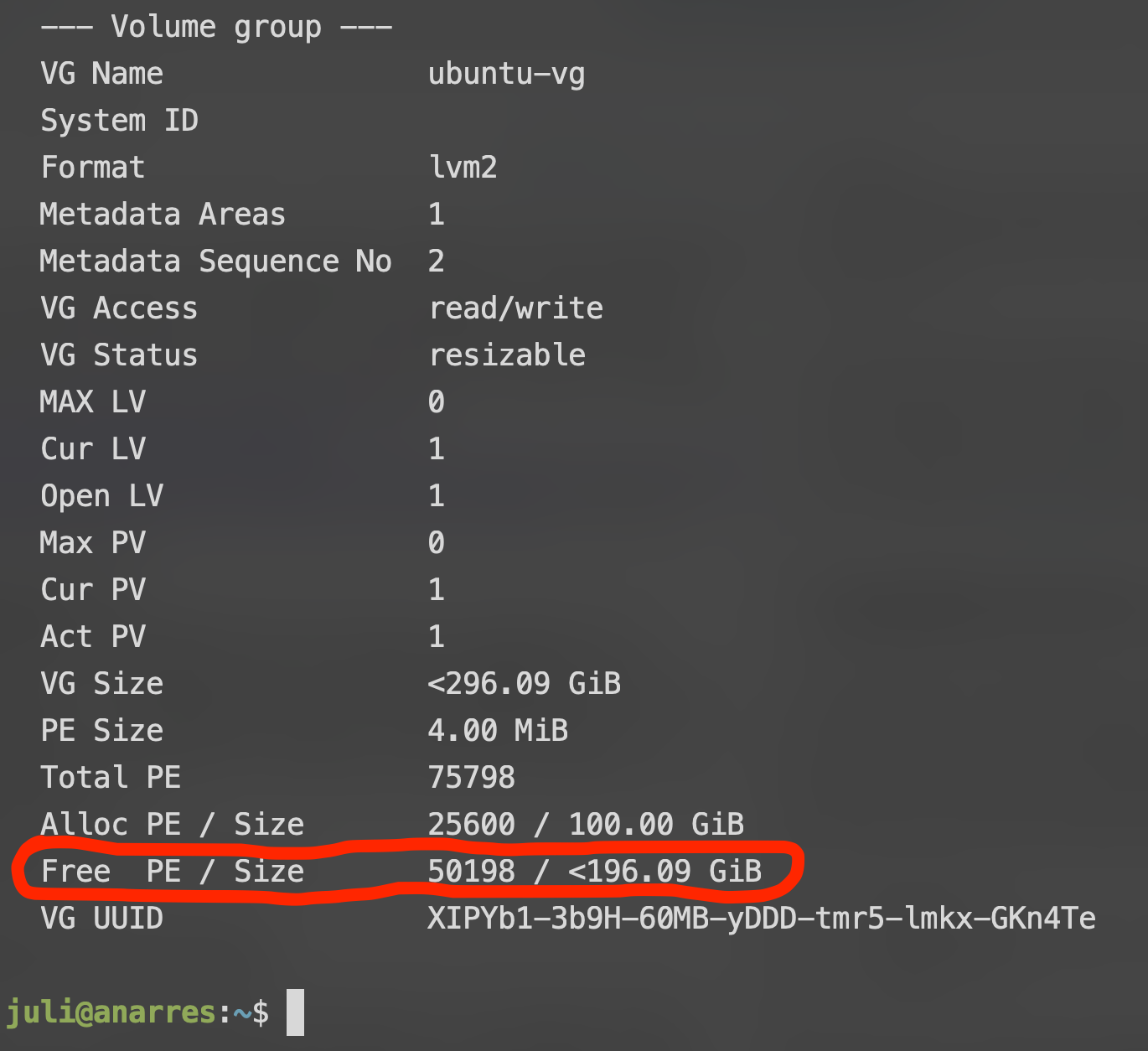
Podemos ver, por ejemplo, que tenemos alrededor de 196 GBs libres, sin utilizar. Armemos un lv con 150 GBs llamado "navidrome". Para hacer esto, vamos a utilizar el comando lvcreate, que se escribe de la siguiente forma:
lvcreate -L <tamaño> -n <nombre> <vg del que obtenemos el espacio>
Como en todo lo que es linux, es importante prestar atención a las mayúsculas y minúsculas en lo que escribimos. La opción "-L" es con L mayúscula, mientras que la opción "-n" es con n minúscula.
El nombre el vg lo podemos ver en lo que nos devolvió el vgdisplay más arriba: es "ubuntu-vg". Así que, con esto en mente, el comando que tendríamos que escribir es:
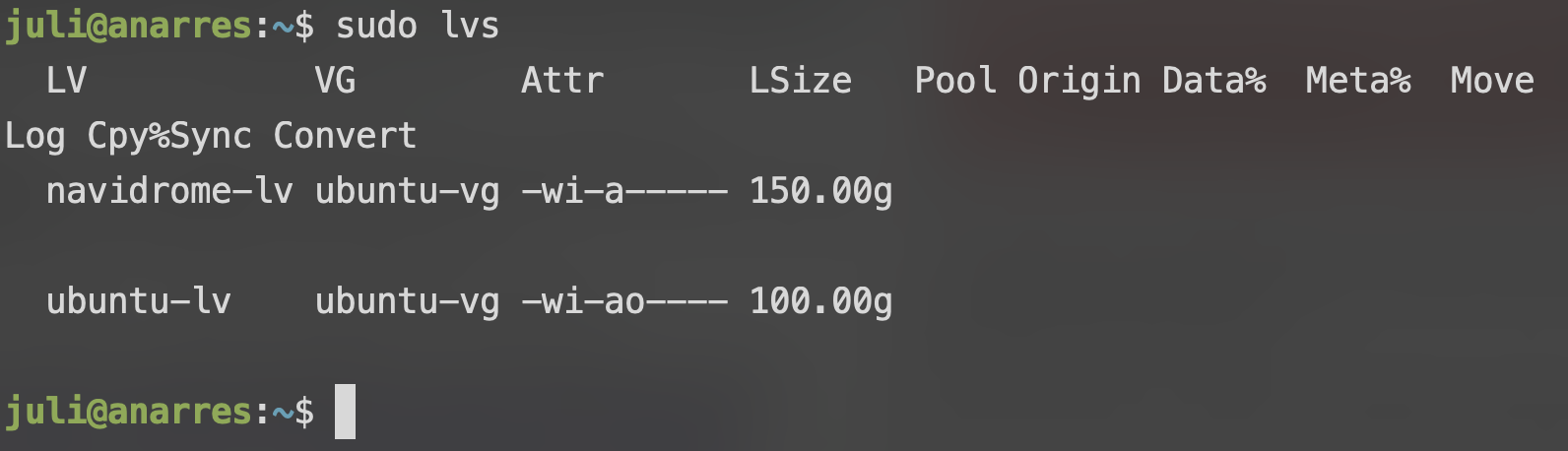
sudo lvcreate -L 150G -n navidrome-lv ubuntu-vg

Ya creado, podemos verlo usando el comando sudo lvs:
Sin embargo, todavía no lo podemos usar; tenemos que formatearlo con un sistema de archivos y tenemos que montarlo en algún directorio. Para esto, necesitamos ver dónde está ubicado el disco; en Linux, todo es un archivo. Esto significa que la mayoría de las cosas (dispositivos como el teclado, discos rígidos, los logic volumes, o los mismos programas que corremos) figuran en el navegador como archivos (o, más bien, abstracciones de lo que representan a archivos). Para ubicar nuestro nuevo lv, vamos a buscar en el mapper, que son como "accesos directos" a los discos:
ls /dev/mapper
Esto nos va a mostrar los dispositivos de almacenamiento que tenemos disponibles en el server:

En este caso, podemos ver que tenemos esas dos opciones:
Nos interesa formatear el lv de navidrome, así que vamos a utilizar su dirección: /dev/mapper/ubuntu--vg-navidrome--lv
El comando que vamos a utilizar es mkfs, específicamente vamos a usar su variante que formatea el archivo a ext4; mkfs.ext4:
sudo mkfs.ext4 /dev/mapper/ubuntu--vg-navidrome--lv
Una vez formateado el volumen, estamos listos para montarlo (sería asignarle un lugar en la jerarquía de directorios en donde estén las cosas que contiene; en Windows este proceso se hace automáticamente y figura como D:\\o C:\\, etc.), para esto, primero vamos a crear el directorio al que lo vamos a montar:
sudo mkdir /mnt/musica
Luego, vamos a usar el comando mount:
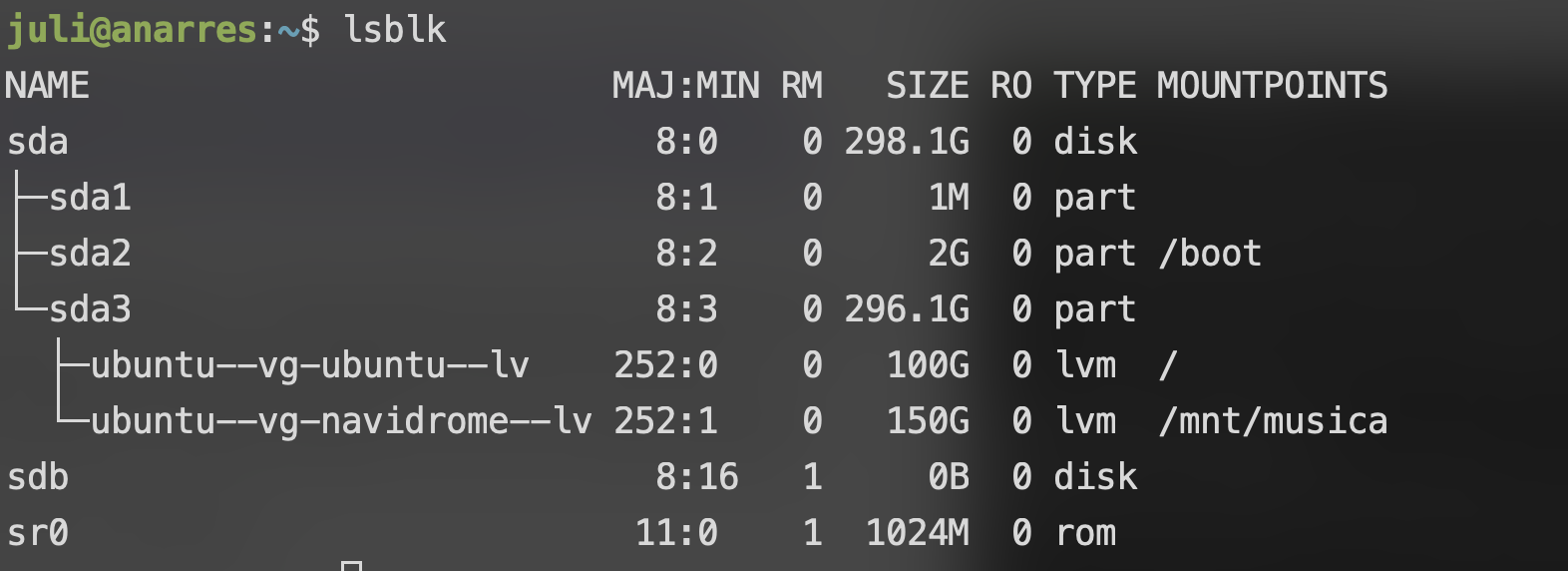
sudo mount /dev/mapper/ubuntu--vg-navidrome--lv /mnt/musica
Y listo! Ya tenemos nuestro volumen montado y listo para usar. Podemos corroborarlo usando el comando lsblk:
Además de esto, podemos ver que figura entre los discos montados cuando usamos el comando para ver el espacio libre df (usamos el "flag" -h para ver el espacio que tienen disponible en unidades "de humanos", MBs y GBs):
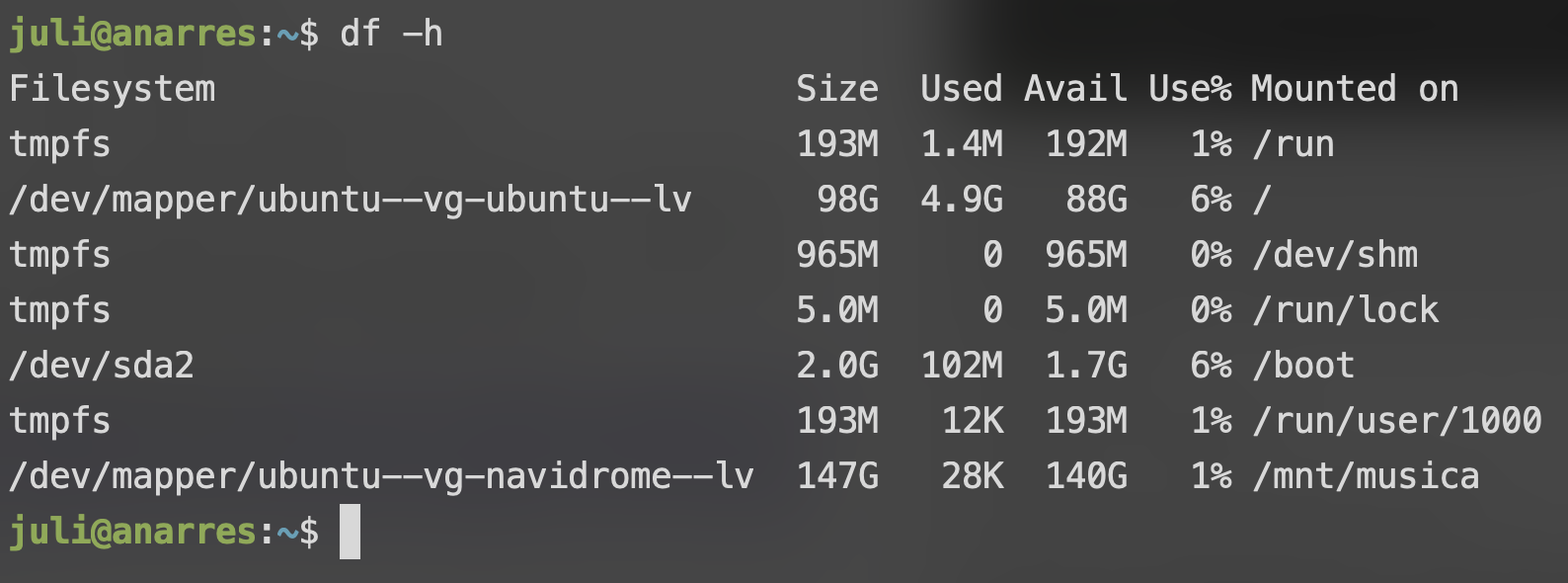
(Es el último elemento de la lista; a la izquierda vemos el dispositivo, el lv, y a la derecha vemos dónde está montado)
Nos queda únicamente un último paso: Encargarnos de que se monte automáticamente cada vez que encendemos la compu. Para esto, vamos a usar un archivo llamado fstab, que está ubicado en /etc/fstab. Vamos a necesitar obtener el UUID del volumen a montar, y para esto vamos a usar el comando lsblk -f (la opción -f es importante acá):
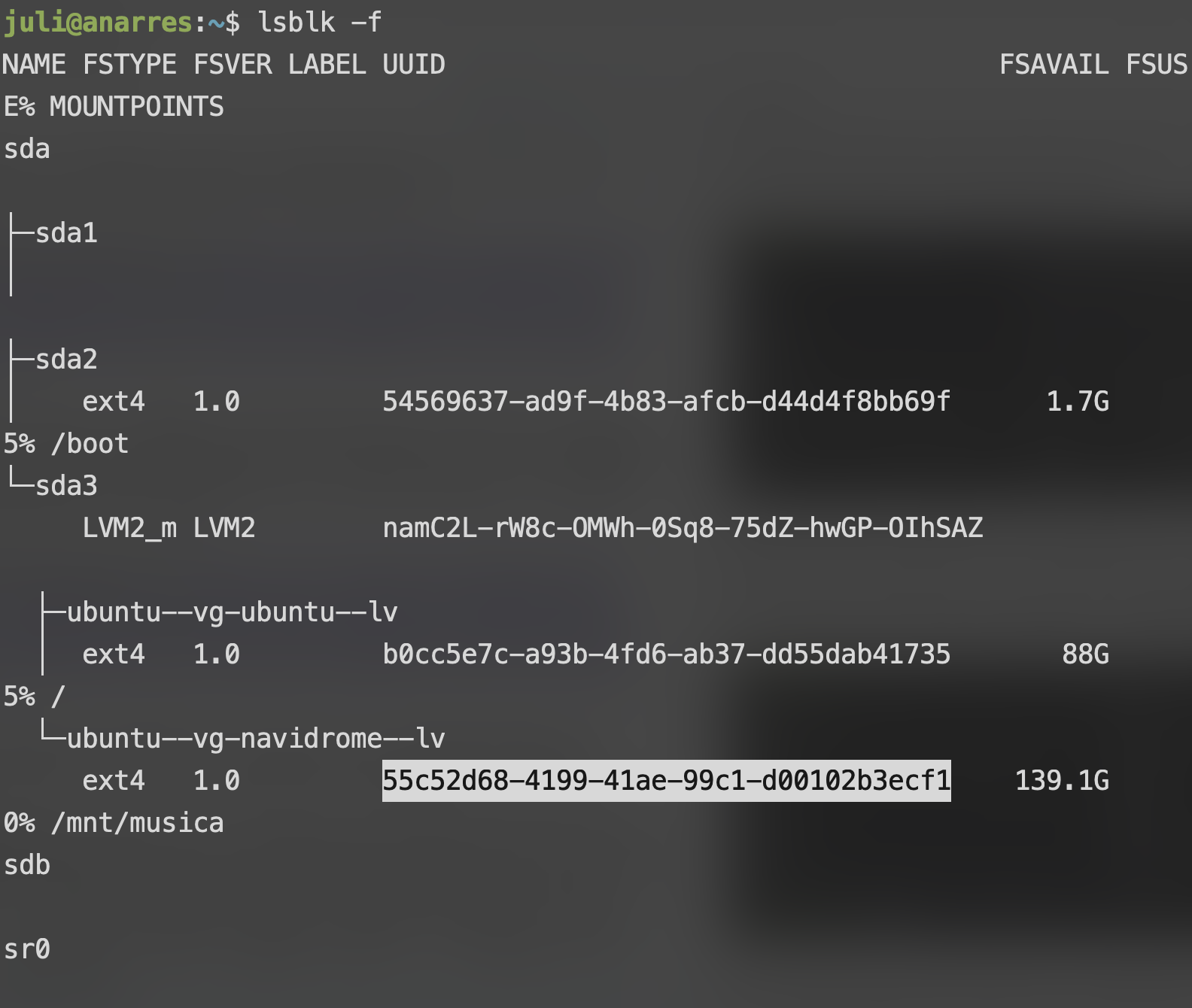
Podemos ver la UUID abajo (si la pantalla es grande, al lado) del volúmen que queremos agregar.
Ahora que tenemos el UUID, lo sumamos al fstab; vamos a tener que abrir el archivo /etc/fstab con un editor de texto (como nano), e instertar la siguiente línea:
UUID=<el UUID del disco> <punto de montado> <formato de sistema de archivos> defaults 0 2
Nótese que el defaults 0 2 va a ser siempre igual; lo que cambia es lo de la izquierda. Para el ejemplo con el que venimos trabajando, sería:
UUID=55c52d68-4199-41ae-99c1-d00102b3ecf1 /mnt/musica ext4 defaults 0 2
Con el comando sudo nano /etc/fstab se nos abre el editor:
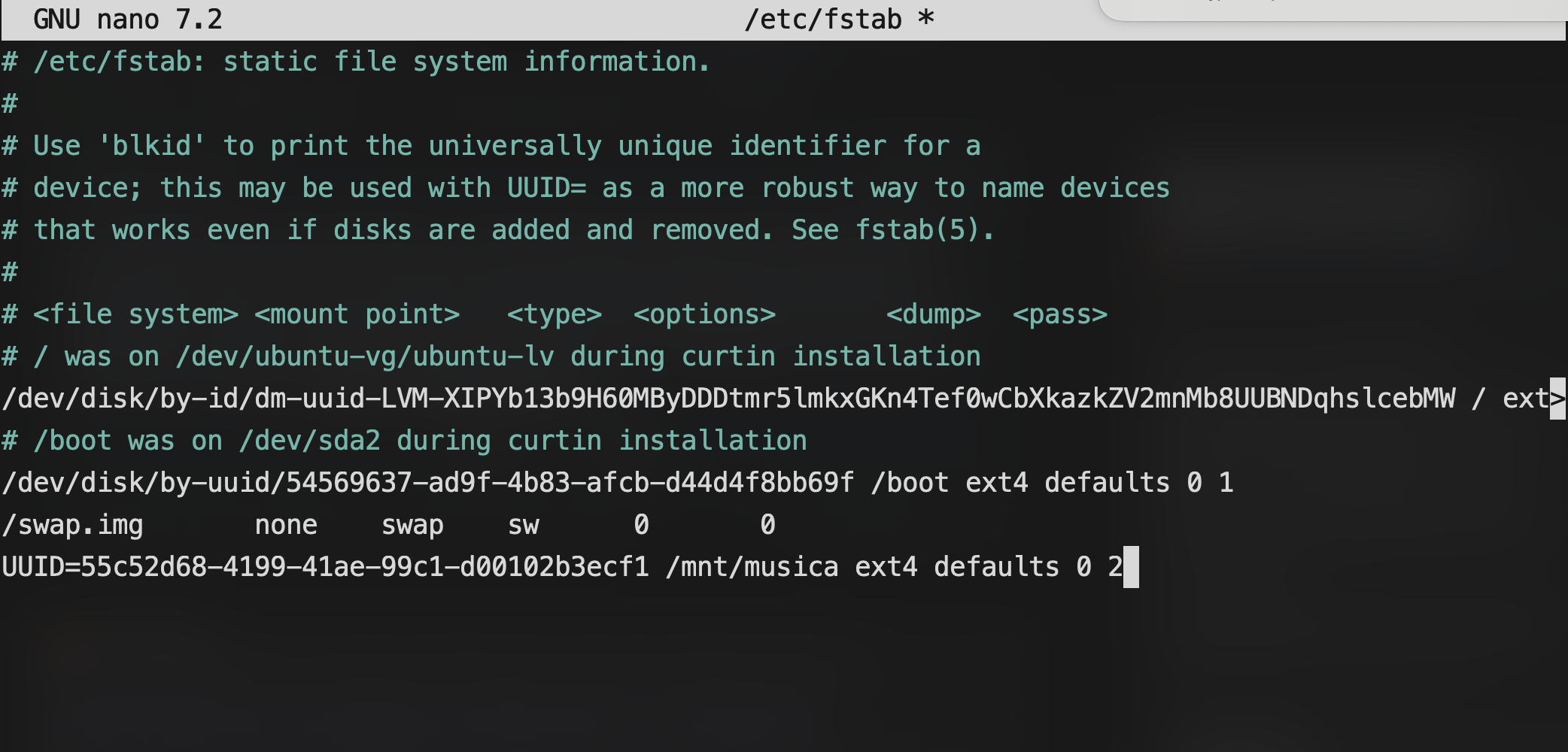
Como siempre, guardamos (en nano) con Ctrl+o y salimos con Ctrl+x.
Una vez hechos los cambios, probamos si nuestro fstab funciona con el comando sudo mount -a, que monta todos los volúmenes que figuran en el fstab:

Como suele pasar en Linux, la ausencia de mensaje se lee como ausencia de error: Todo funcionó bien.
Y ahora sí! Ya tenemos nuestro nuevo volúmen montado y listo para ser utilizado de forma permanente :)
Modificar el espacio de un Logical Volume
Modificar el espacio del que dispone el volumen es simple; utilizamos el comando lvextend para ampliar el espacio, y lvreduce para achivarlo.
Cuando reducimos el espacio de un volumen, hay que tener mucho cuidado; si lo reducimos a un tamaño menor al de los datos que tiene almacenados, es muy probable que perdamos esa información de forma irreversible.
Reducir el espacio de un lv
Para reducir el espacio, como mencionamos más arriba, vamos a usar el comando lvreduce. La sintaxis es muy similar a la de lvcreate que vimos más arriba:
sudo lvreduce --resizefs -L <nuevo tamaño> <volumen a reducir>
En -L, podemos poner un tamaño absoluto, como puede ser 100G para 100 Gbs, o podemos poner un tamaño relativo, como -20G para restarle 20 Gbs al total del volúmen:
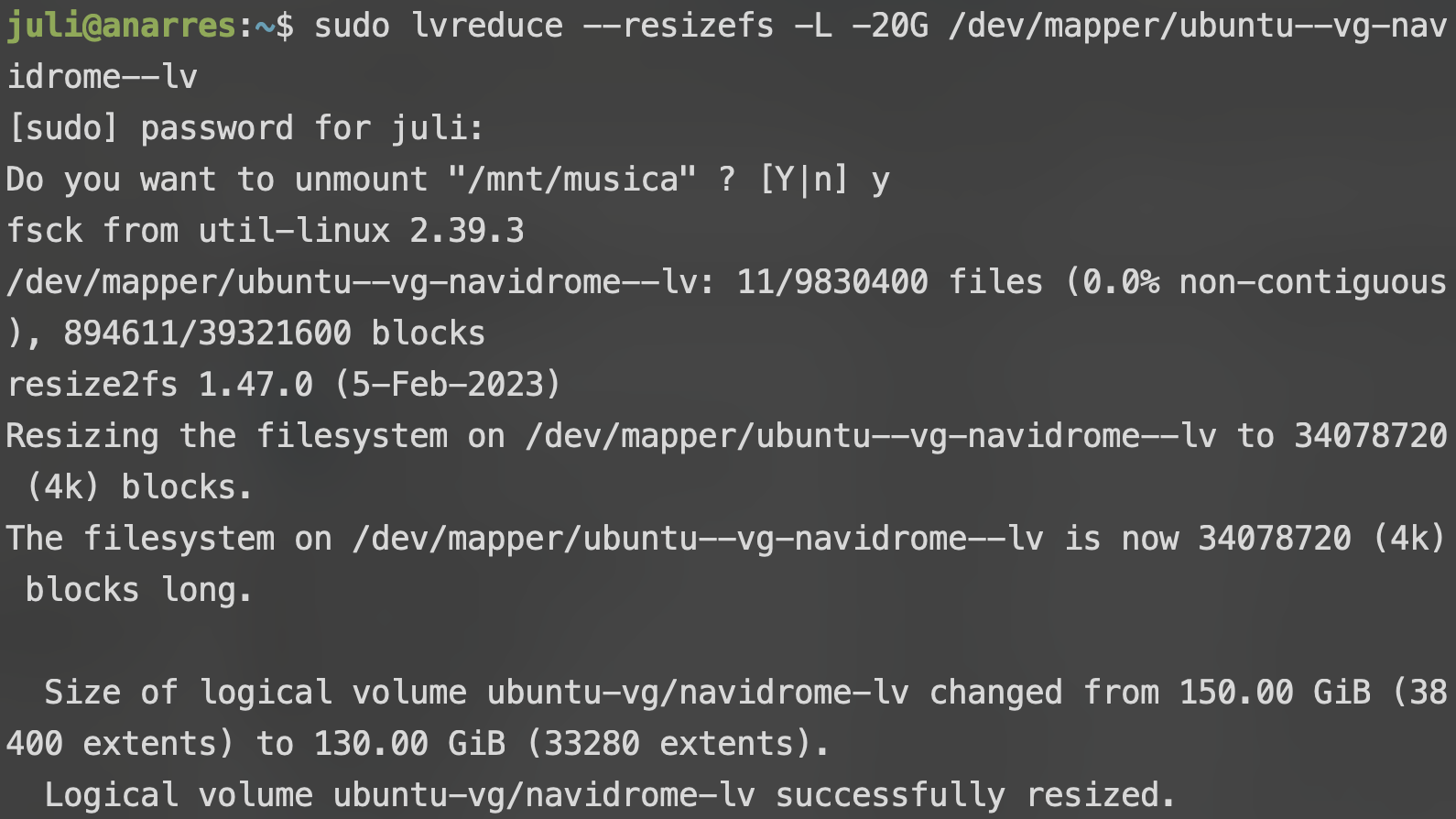
Podemos ver cómo se redujo el tamaño del volúmen de 150 Gb a 130 Gb.
Como podemos ver, para hacer esta operación el programa nos pide desmontar el volúmen. Esto significa que si queremos montarlo de nuevo, vamos a tener que volver a correr el comando mount como vimos más arriba (en la sección de crear un lv).
Expandir el espacio de un lv
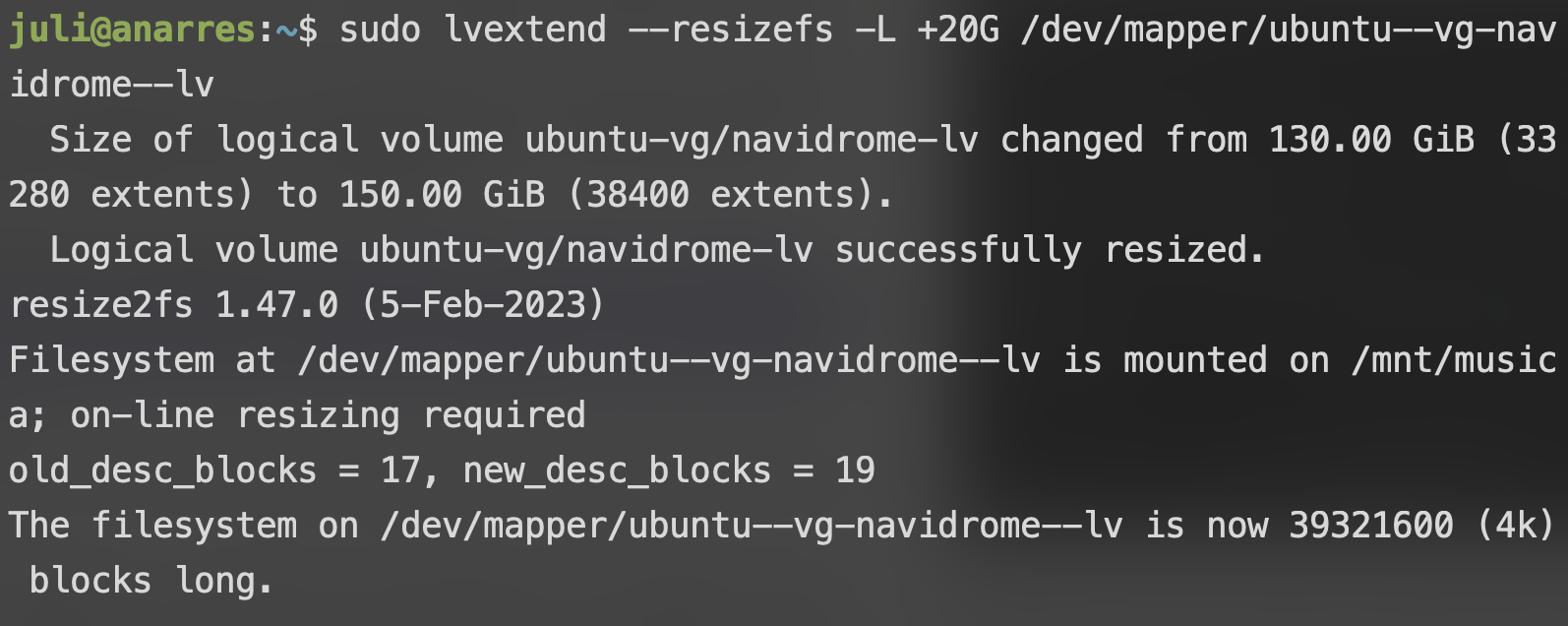
Para expandir el espacio, el proceso va a ser similar al que vimos en cómo reducir el espacio; vamos a usar el comando lvextend:
sudo lvextend --resizefs -L <nuevo tamaño> <volumen a expandir>
Como antes, la opción --resizefs se encarga de que además de cambiar le tamaño del volúmen cambie el tamaño de su sistema de archivos, y la opción -L tamaños absolutos como 50G o relativos como +20G:
Eliminar un Logical Volume
En algunos casos, también, podríamos llegar a querer eliminar un lv. El proceso para hacerlo es simple, pero siempre hay que tener mucho cuidado, ya que podemos perder permanentemente la data almacenada en ese volúmen.
La única consideración es que, antes de eliminarlo, debemos desmontarlo con el comando umount (sí, no unmount, umount)
sudo umount /mnt/musica
(nótese que usamos el lugar donde está montado, no la "dirección del volúmen")

Hecho esto, vamos a usar el comando lvremove para eliminar el volúmen:

Y listo, el volúmen ya no existe más.
Como tuvimos que agregarlo al fstab cuando lo creamos, ahora deberíamos eliminarlo de la lista modificando nuevamente el archivo /etc/fstab, eliminando la línea que lo monta al encender la computadora. (Revisá la sección de cómo crear un Logical Volume para ver más info al respecto)
Servicios
En este capítulo, vamos a encontrar páginas sobre distintos servicios (programas pensados para ser accedidos por "clientes" y ser utilizados)
Navidrome
Qué es Navidrome?
Instalar Navidrome
La instalación de Navidrome es muy simple, ya que la realizamos a través de docker, usando específicamente su plugin docker compose. (Acá podemos ver un desglose básico de cómo funciona el docker compose.)
Crear directorios
Lo primero que vamos a tener que hacer va a ser designar un directorio para muestra música y otra para nuestra data (data, en este caso, refiere a cosas como lxs usuarixs que creemos, las playlist, favoritos, y demás de ellxs, cosas así). El directorio de la música podría ser el que antes definimos a través del lvm (ver en prerrequisitos), o podría ser un directorio nuevo que creemos. Para este ejemplo, vamos a suponer que el directorio para nuestra música se va a encontrar en /mnt/musica, ya que lo creamos para montar un [volumen lógico] específico allí. Nuestro directorio de data lo vamos a crear en nuestro directorio home, en la siguiente dirección: ~/docker/navidrome/data (~ representa el path a nuestro directorio home):
mkdir -p docker/navidrome/data

Crear y configurar docker compose
Hechos nuestros directorios de música y data, vamos a crear un archivo llamado docker-compose.yaml. Este archivo lo podemos hacer donde queramos, pero yo normalmente creo un directorio llamado composes en el directorio de docker, y dentro de ese directorio creo directorios con los distintos servicios que voy a subir (ya que el archivo donde vamos a poner el docker compose siempre se va a llamar docker compose):
mkdir -p ~/docker/composes/navidrome
nano ~/docker/composes/navidrome/docker-compose.yaml
Dentro del archivo docker-compose, vamos a copiar lo siguiente:
services:
navidrome:
image: deluan/navidrome:latest
user: 1000:1000 # should be owner of volumes
ports:
- "4533:4533"
restart: unless-stopped
# environment:
# Optional: put your config options customization here. Examples:
# ND_LOGLEVEL: debug
volumes:
- "/path/to/data:/data"
- "/path/to/your/music/folder:/music:ro"
Vamos a tener que prestar atención a dos cosas:
- Que el usuarix 1000 sea dueño de los volúmenes (los directorios) donde almacenemos nuestra música y data
- Que modifiquemos el path hacia los volúmenes correctamente
Chequear que lx usuarix sea dueñx de los volúmenes
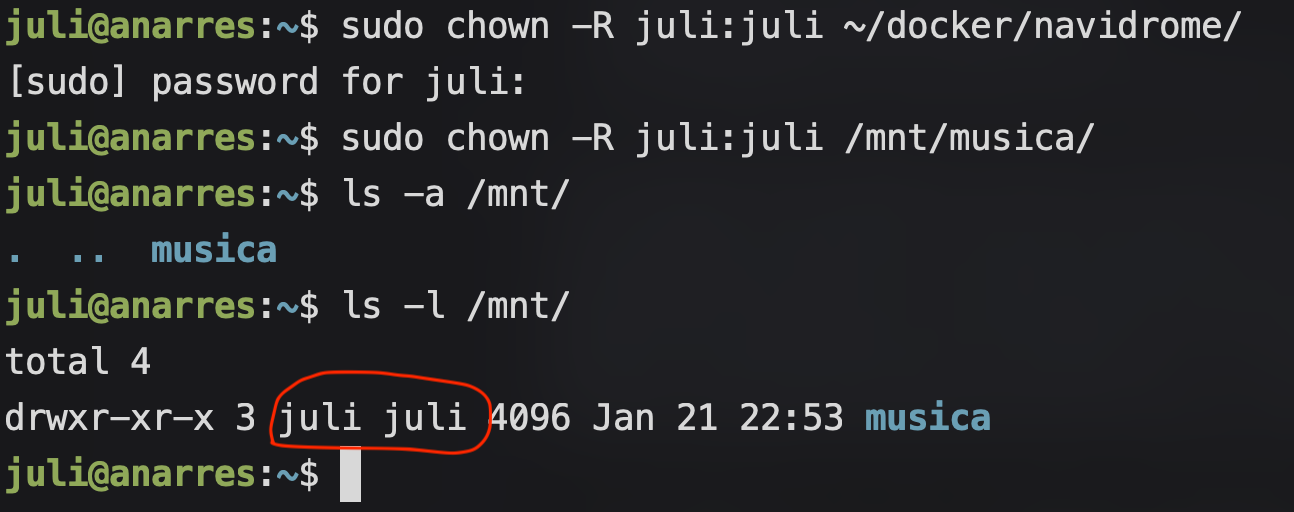
Para chequear que tengamos acceso a los volúmenes vamos a usar el comando chown, que cambia lx dueñx de un archivo o directorio. Lo vamos a usar con la opción -R para asegurarnos de que ese cambio sea recursivo, es decir que también cambie lx dueñx de los directorios y archivos dentro del directorio que indiquemos. En este ejemplo, nuestros directorios a cambiar son ~/docker/navidrome y /mnt/musica, y lx usuarix que queremos que pase a ser su dueño va a ser juli:
sudo chown -R juli:juli ~/docker/navidrome
sudo chown -R juli:juli /mnt/musica
Podemos ver cómo, por ejemplo, lx usuarix juli figura como dueñx de /mnt/musica:
Indicar los path hacia los volúmenes
Para esto, simplemente vamos a tener que modificar dos líneas de nuestro archivo docker-compose.yaml:
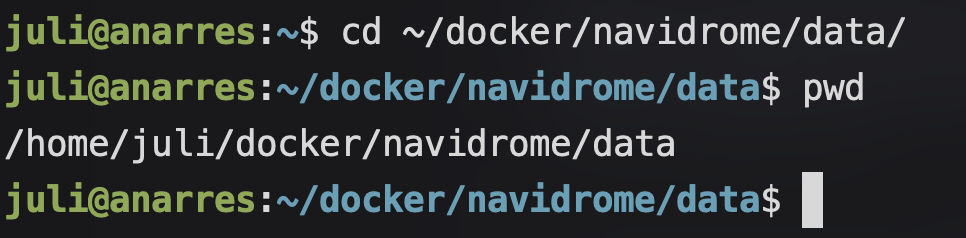
"/path/to/data:/data": Vamos a tener que cambiar /path/to/data al path de nuestra carpeta de data. Para esto recomiendo que usemos paths absolutos, es decir sin usar ni el ~, ni el .. Entonces, si queremos averiguar cuál es el path absoluto hacia nuestro directorio de data, podemos usar cd para dirijirnos ahí y luego el comando pwdpara ver su path:
cd ~/docker/navidrome/data
pwd
Ahora que vimos el path, podemos cambiar la línea (recordá que para abrirlo, o incluso crearlo, tenés que usar el comando nano docker-compose.yaml desde dentro de la carpeta donde se encuentra el archivo):
"/path/to/data:/data" --> "/home/juli/docker/navidrome/data:/data"
Con /mnt/musica no necesitamos hacer esto, ya que como el path comienza con una barra diagonal, sabemos que es un path absoluto.
"/path/to/your/music/folder:/music:ro" --> "/mnt/musica:/music:ro"
Iniciar el contenedor
Cambiadas estas dos líneas, el docker-compose.yaml nos debería haber quedado así:
services:
navidrome:
image: deluan/navidrome:latest
user: 1000:1000 # should be owner of volumes
ports:
- "4533:4533"
restart: unless-stopped
# environment:
# Optional: put your config options customization here. Examples:
# ND_LOGLEVEL: debug
volumes:
- "/home/juli/docker/navidrome/data:/data"
- "/mnt/musica:/music:ro"
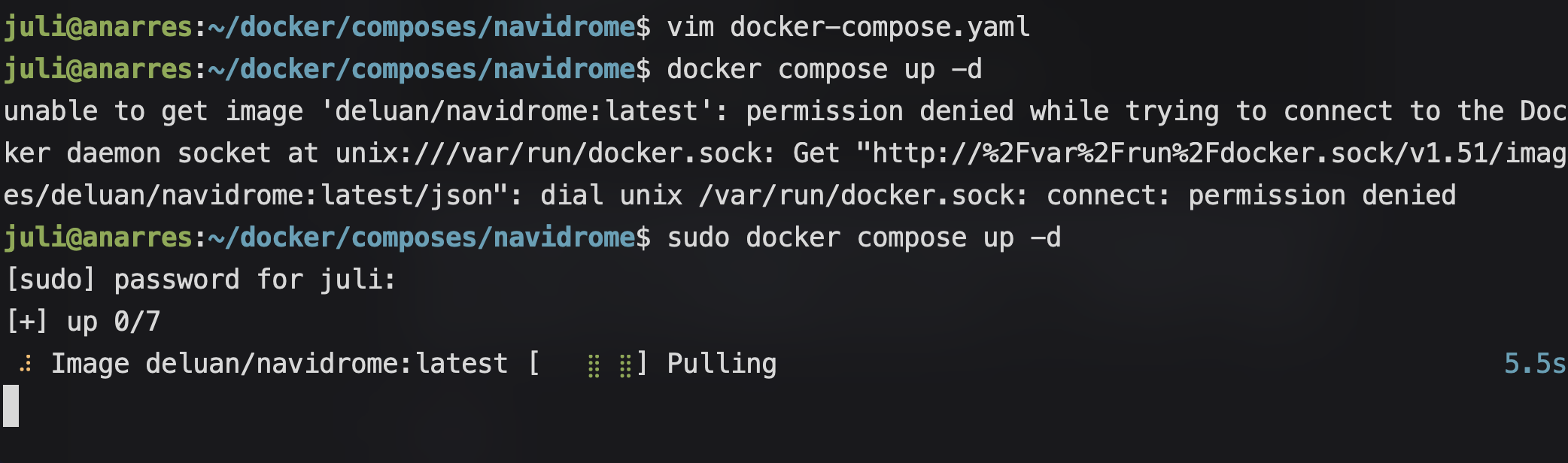
Ahora, lo único que nos queda es arrancar el servicio. Después de guardar los cambios y salir del archivo, ejecutamos (dentro del directorio donde se encuentra el archivo docker-compose.yaml) el comando docker compose up -d (puede que nos haga algún problema, y si es así, deberíamos correrlo con sudo: sudo docker compose up -d):
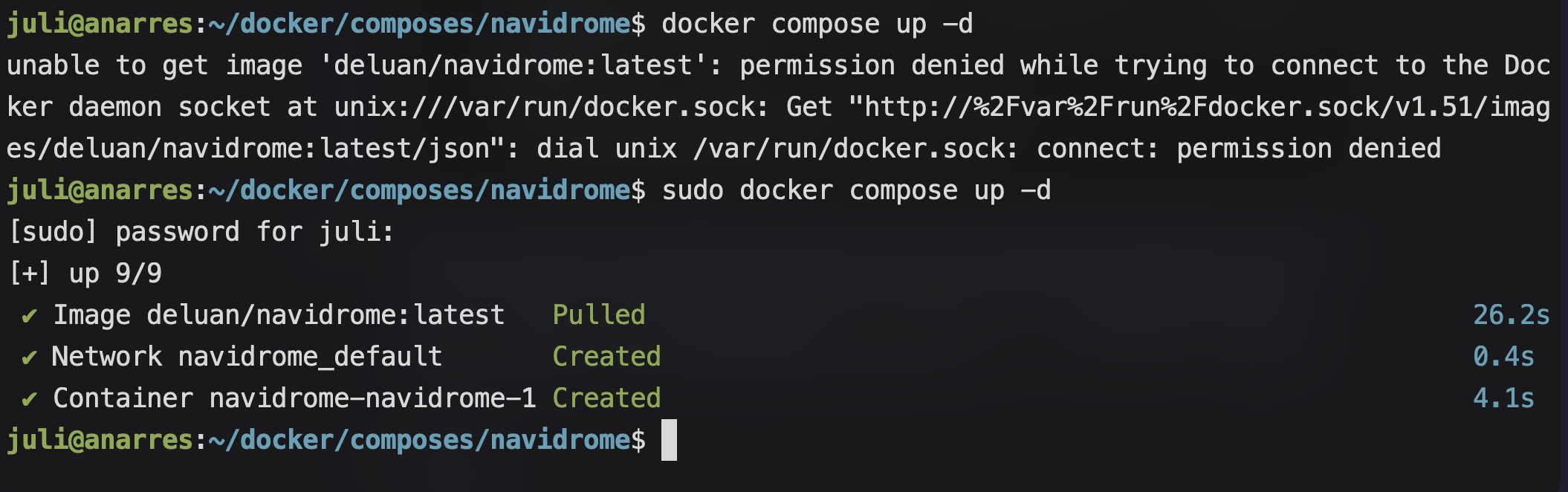
Acceder al contenedor y crear usuarix Admin
Una vez creado el contenedor, nuestro serivico ya va a estar corriendo! Podemos acceder a él usando la dirección <ip-del-servidor>:4533 en nuestro navegador de internet:
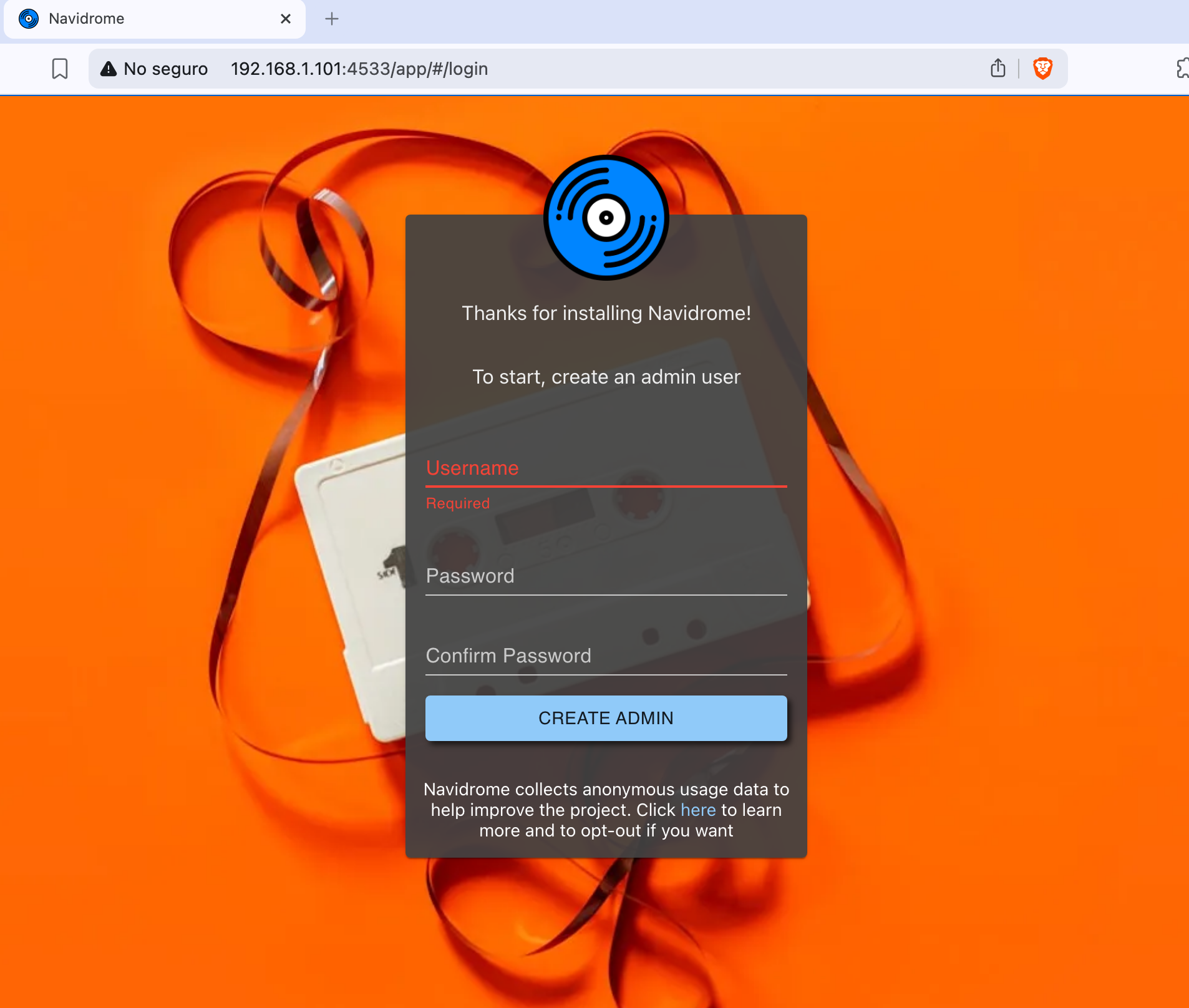
Como podemos ver, lo primero que nos pide va a ser crear un usuarix admin. Este usuarix es quien va a poder crear nuevas cuentas para otra gente y adminisitrar, por lo general, el servicio.
- Instalar algún servicio para procurar música directamente a nuestro servidor
- Usar Cockpit para trasladar música a nuestro servidor
- Bajar alguna aplicación de música que utilice subSonic y conectarla al servicio
En principio, ya podés disfrutar de tu spotify casero!
Glosario
Capítulo que va a contener varias definiciones de conceptos teóricos que pueden ser necesarias de aclarar para las distintas cosas a llevar a cabo
Direcciones IP
Para este artículo, y por simplicidad del tema, vamos a estar hablando de IPv4, y no de IPv6, ya que esta última no desplazó a IPv4 todavía, y es la que se nos asigna en la mayoría de los casos a quienes usamos computadoras conectadas a internet.
Si no sabés de qué habla lo de arriba, no te preocupes :) Seguí leyendo
Qué son las direcciones IP?
Cuando las computadoras se conectan a internet, o a cualquier red, utilizan una "dirección", como la dirección de tu casa, única que les permite identificarse ante el mundo y compartir información con otras computadoras. Desde ya que las otras computadoras también tienen direcciones como la tuya. Estas direcciones se llaman direcciones IP. Su formato son cuatro números del 0 al 255 separados por puntos, por ejemplo: 155.42.3.23.
El problema con las IPs
Sin embargo, las IP tienen una limitación. Al sólo poder ser estos cuatro números, y al sólo poder ir del 0 al 255, tienen cómo límite 4.300 millones de combinaciones. Esto parece un montón, pero recordemos: Cada "computadora", cada aparato electrónico que se pueda conectar a internet, debería tener una. Esto incluye:
- Celulares
- Relojes "inteligentes"
- Lamparitas "inteligentes"
- Heladeras
- Sensores
- Y muchas otras cosas
Por esto, y sobre todo desde que se empezaron a crear cada vez más tipo de dispositivos conectados a interent, empezó a crecer la preocupación por que se acaben las direcciones de IP. Para solucionar este problema, se decidió separar una cantidad de rangos de IP que no podrían ser utilizados en el internet, y se reservarían para redes locales.
IPs locales
Como solución, estos rangos de IP sólo podrían ser usados en las redes de cada casa, empresa, o lo que sea, y cuando se conectasen a internet, lo harían con la IP del router. De esta forma, una red de casa que conteniese, por ejemplo, 200 dispositivos conectados, sólo tendría una sóla IP a través de la cual se conectaría a internet. Y el dispositivo encargado de hacerlo(el router), tendría la responsabilidad de, cada vez que una computadora externa se conecte con la IP de la casa, "derivar" a la computadora externa hacia la IP local que le corresponda.
Cómo sabemos si una IP es local o de internet
Como mencioné más arriba, las IPs locales pertenecen a un rango específico. Estos son:
- 10.0.0.0 - 10.255.255.255
- 172.16.0.0 - 172.31.255.255
- 192.168.0.0 - 192.168.255.255 <- Estas son las que más vi
Por lo tanto, por ejemplo, la dirección 192.168.10.46sería una dirección local, igual que 172.20.0.157, mientras que direcciones como 172.40.54.23o 192.170.23.4 no lo serían.
Puertos
Los puertos, o ports, en inglés, son esencialmente puntos de conexión de nuestras computadoras hacia otras computadoras. Todas las computadoras se conectan entre sí mediante puertos. Es decir, cualquier conexión que ocurra de una computadora a otra va a ocurrir mediante puertos.
Rango de puertos
Los puertos están numerados: Pueden ser desde el puerto 0 al puerto 65535. Sin embargo, no todos estos puertos son iguales:
- 1-1023 Puertos conocidos: Son puertos reservados para servicios fundamentales, como e-mail, http o https(los protocolos de internet)
- 1024-49151 Puertos registrados: Los puertos "de uso común" por varios programas. No tienen un uso específico como los anteriores, y son los puertos que normalmente usan las varias aplicaciones que podemos correr en nuestra computadora.
- 49152-65535 Puertos dinámicos: Son puertos que utilizan varios servicios de nuestra computadora automáticamente. No conviene que los usemos nosotrxs manualmente.
Ejemplos de puertos conocidos y usados
| Puerto | Servicio | Descripción |
|---|---|---|
| 80 | http | Protocolo de internet |
| 443 | https | Protocolo de internet(seguro, el candadito |
| 22 | ssh | Protocolo de "terminal remota" secure shell |
| 21 | ftp | Protocolo de FTP(File transfer protocol) |
| 25 | smtp | Protocolo de e-mail |
| 7878 | radarr | Puerto por defecto utilizado por el programa "radarr" |
| 8096 | jellyfin | Puerto por defecto de la aplicación "Jellyfin" |
Vale destacar que los últimos dos puertos del ejemplo, al ser puertos de la sección de "puertos registrados", pueden llegar a ser usados por otros progamas también. Cuando se instala, por ejemplo, Jellyfin, si el puerto ya está en uso, se puede aclarar al programa que debería utilizar otro.
Dominios
Los dominios son las "direcciones legibles por humanos". Son, por ejemplo google.com, que nos dirige a la IP de google. Los dominios están distribuídos a distintas empresas que los alquilan, o a distintos países que hacen igual. Los dominios de máximo nivel (Top Level Domain, o TLD), por ejemplo, ".com.ar" y ".ar", le corresponden al Estado Argentino, y se consiguen en la página "nic.ar". Hay muchos dominios que son vendidos por entidades privadas, como los dominios ".xyz", ".lat", o incluso los ".com". Páginas que normalmente venden dominios incluyen:
Permisos en Linux(y UNIX)
Esta página aún no fue escrita
Sinopsis
Permisos
Root
SUDO
La Terminal
La terminal (a veces llamada tambíen "consola" o "command line interface"(cli)) es la principal forma de interactuar que vamos a tener con nuestro servidor, especialmente si éste no tiene una interfaz gráfica.
En realidad, todo corre a través de la consola; la interfaz gráfica simplemente nos genera un entorno más "amigable" y, bueno, gráfico, para interactuar con ella, en lugar de "comandos de texto". (Envía dichos comandos de texto por nosotrxs)
Tutorial: conceptos básicos de la consola
Si estás acá es porque ya estamos manejándonos usando la consola como principal forma de interactuar con el server. No paniquees! Es mucho más simple de lo que parece. Ante todo, si querés un tutorial un poco más completo, aunque en inglés, recomiendo este de acá. Si preferís algo más superficial, sigamos!
Qué es la consola?
La consola, simplemente, es un programa que nos permite interactuar con la computadora a través de comandos de texto. Para abrir una, en Linux o Mac, simplemente tenés que buscar el programa "Terminal". En caso de que tengas Windows, la "consola" que tienen ellos se va a llamar la Command Prompt (en español, si no me equivoco, "Símbolo del Sistema", y en ambos idiomas se encuentra como "CMD", también).
IMPORTANTE! En este tutorial, todo lo que veamos va a aplicar a consolas de Linux o macOS (sistemas operativos basados en "UNIX", un sistema operativo abuelito suyo). Si querés seguir el tutorial desde Windows, te recomiendo que busques el "WSL" (Windows Subsystem for Linux), o que lo hagas ya desde una conexión "ssh" con tu servidor.
Si te conectaste por [ssh], felicitaciones! Ya estás usando una terminal.
Lo fundamental
Cuando trabajamos en una terminal (sea con una [conexión remota mediante SSH], o abriendo un "emulador de terminal" (a veces llamado simplemente terminal) o en la consola misma de la computadora, estamos esencialmente usando un programa que espera que corramos "comandos" indicándole qué hacer. Este programa funciona de forma similar al navegador "explorer" de Windows o el "finder" de mac, en un sentido: Los comandos que corramos, va a correrlos en el contexto de una ubicación específica. Cuando recién lo abrimos, esa ubicación suele ser el directorio "home" de nuestro usuario. Por ejemplo, una sesión recién abierta se podría ver así:

Parecen cosas al azar, pero en realidad, la consola nos muestra toda información importante para tener en cuenta:
- Al comienzo, y la izquierda de la
@, podemos ver qué usuario está usando la consola (con quién nos logueamos). Este usuario, por ejemplo, se llamafulano. - Del otro lado de la
@(que en inglés significia "at", es decir, "en"), tenemos el nombre de la computadora a la que estamos conectadxs, en este casowaystone-inn. Si leemos ambas secciones juntas, se podrían traducir a "fulanoen la computadorawaystone-inn". - Después de los dos puntos, tenemos la dirección en la que estamos trabajando. El símbolo
~simboliza nuestro "home", o carpeta "hogar" de nuestro usuario. Esta carpeta es sólo nuestra, y ningún otro usuario (salvo lxs administradorxs) puede acceder a ella a menos que decidamos permitírselo. - Finalmente, el símbolo
$representa que esta sesión es de un usuario común, que no es un administrador (en realidad, que no estamos actuando a través del usuario especialroot, que es un usuario cuyos todos comandos son corridos como de administración. En ese caso, veríamos un#en su lugar). - Finalmente finalmente, vemos el cursor de texto, esperando que escribamos algo.
Qué pasaría si corremos un comando? Probemos con "pwd", que como su nombre indica (path to working directory), nos muestra cúal es el "camino" hacia el directorio de la carpeta en la que estamos trabajando siguiendo la [[estructura jerárquica de directorios]] de Linux. Ingresamos pwd, y tocamos "enter" para enviar el comando, y obtenemos esto:
 Después de tocar "enter", la computadora nos responde con la dirección al directorio actual (
Después de tocar "enter", la computadora nos responde con la dirección al directorio actual (/home/fulano, es decir que desde la carpeta base, conocida como /, entraríamos a la carpeta home, y dentro de ésta estaría la carpeta fulano), y en otra línea nos figura la misma info que antes, simbolizando que nuevamente tenemos control sobre la computadora (y nuevamente está esperando una indicación o comando).
Es importante notar que cuando ingresamos "pwd", no tuvimos que aclarar a dónde era esto, ya que la consola dio por sentado que nos referíamos al directorio en el que nos encontrábamos. Veamos un ejemplo distinto. Si la consola nos mostrase, después de los dos punto, esto:
 Nos estaría indicando que no estamos trabajando el el directorio "home" de nuestro usuario, sino en el directorio que se encuentra en la ruta
Nos estaría indicando que no estamos trabajando el el directorio "home" de nuestro usuario, sino en el directorio que se encuentra en la ruta /var/log/apt. Si corriésemos el comando pwd, por más redundante que sea, nos mostraría como resultado que, en efecto, ese es el "camino" hacia la carpeta en la que estamos trabajando, y que la consola da por sentado que estamos corriendo el comando desde esa ubicación en los directorios del sistema:
 .
.
De la misma forma, y volviendo al directorio "home" (que figura como un ~ en nuestra consola, para abreviar), si usásemos el comando touch, que sirve para crear un archivo vacío, y se utiliza escribiendo touch <nombre del archivo>, el archivo creado lo encontraríamos en el actual directorio:
 Un par de cosas para notar:
Un par de cosas para notar:
- Los archivos en Linux no necesitan llevar una extensión. Por lo general, si no indican nada, suelen ser archivos de texto, aunque a veces son binarios también. No nos importa mucho esa distinción, sí nos importa saber que muchos programas usan la extensión para saber cómo tratar al archivo, así que, aunque no sea necesaria (como en el ejemplo), es mejor ponerla por las dudas (en este caso, podría haber agregado
.txtal final, por ejemplo). - En Linux, si un comando no te dice nada cuando lo corrés, y asumiendo que es un comando que no nos da información específicamente (como
pwd), *significa que el comando se corrió con éxito`.
Pero, bancá un segundo. Cómo sabemos que se creó el archivo? Bueno, es que el comando touch sólo crea el archivo, y siguiendo la filosofía Unix de crear herramientas que sólo hagan una cosa y la hagan bien, no hace más nada. Ni siquiera nos muestra el archivo. Para verlo, podemos usar el comando ls, que nos lista los archivos y directorios dentro del directorio en el que nos encontramos:
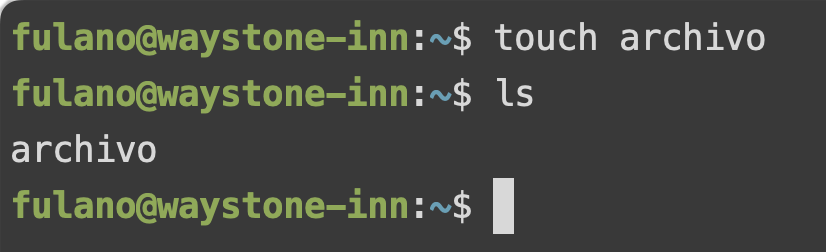 Podemos ver, ahora, que el archivo está en la carpeta en la que estamos (y, de paso, que es el único archivo presente).
Podemos ver, ahora, que el archivo está en la carpeta en la que estamos (y, de paso, que es el único archivo presente).
Más abajo vamos a ver, entonces, varios comandos que podemos utilizar en la consola para navegarla y modificarla, creando archivos, copiándolos, cambiándoles el nombre y más.
Navegando
Comando cd
Comando ls
Creando archivos y directorios
Comando mkdir
Comando touch
Copiando, moviendo y eliminando
Comando mv
Comando cp
Comando rm
Editando archivos de texto
Comando nano
SSH
El SSH (Secure SHell) es un protocolo para acceder al "shell" (la consola o terminal, en pocas palabras) de una computadora de manera remota. Es la principal forma en la que vamos a interactuar con nuestro servidor, ya que es más cómodo por lo general acceder y configurar las cosas desde nuestra computadora de siempre y tener el server guardado en algún recoveco donde no moleste.
Acceder a un servidor a través de SSH
Usar SSH desde una Mac o desde una computadora con Linux es extremadamente simple, ya que el programa para hacerlo suele venir preinstalado en las mismas. En el caso de Windows, si usás Windows 10 u 11 (y los tenés al día), tambíen deberías poder hacer algo parecido. Si no, tendrías que instalar un cliente de SSH, como putty.
En caso de tener ssh instalado, el proceso es simple (y si no lo tenés instalado, dejo en vos googlear como instalar el cliente ssh en tu sistema operativo (el de tu compu de siempre, no el del server):
Abriendo la terminal (o símbolo de sistema/terminal en Windows), ingresamos el siguiente comando:
ssh <usuario>@<ip del servidor>
Al hacerlo, nos va a preguntar si queremos "guardar el fingerprint" del servidor al que accedemos. Indicamos que sí (esto va a pasar únicamente cuando accedemos por primera vez a una computadora nueva), y nos va a pedir la contraseña. Una vez que la ingresemos, vamos a haber accedido a una consola remota del servidor. Desde ahí, vamos a poder hacer todo lo que haríamos sentados frente a una terminal en la misma computadora.
Si no sabés qué hacer acá, y nunca usaste una terminal antes, podés ver los conceptos básicos acá, o leer la guía más completa (y muy buena y didáctica) que recomiendo en esa misma página, acá.
Gestor de paquetes (Package manager)
Gestor de paquetes
Qué es un gestor de paquetes?
En la mayoría de las distribuciones de Linux se incluye un "Package manager" o "Gestor de paquetes". Esto es un programa que, esencialmente, se encarga de bajar otros programas por nosotros. Sería el antecesor de lo que hoy son las "App Stores" en los celulares. Al igual que las app stores, además de bajar e instalar paquetes, este programa se utiliza también para actualizar, mantener y eliminar las cosas que instalamos con ellos. En ese sentido, nos simplifica un poco las cosas: En lugar de tener que bajar archivos, instalar drivers y dependencias, y demás, sólo tenemos que bajar un cierto paquete y el programa instala todo lo necesario para que funcione.
apt
apt es el gestor de paquetes instalado por defecto en Ubuntu, y en todos los distros de Linux basados en Debian (como Ubuntu lo es). Vamos a usarlo seguido en nuestro servidor, y frecuentemente, ya que los siguientes dos comandos, apt update y apt upgrade, son los que se encargan de actualizar todos los paquetes (programas) que instalemos a través de este método. Ambos comandos deben ser ejecutados como administrador. El comando normalmente escrito para actualizar sería:
sudo apt update && sudo apt upgrade
(el && significa que, si el primer comando se corrió con éxito, se pueda correr el segundo)
Para instalar los paquetes sin que nos pregunte si aceptamos instalar cada uno, podemos correr en cambio:
sudo apt update && sudo apt upgrade -y
Docker
Este artículo todavía no existe :3
Docker
Acá va a ir la definición de Docker
Docker compose
Acá voy a explicar cómo funciona docker compose
ToDo
Delineado de artículos pendientes para la guía
- Página de partida/índice (va a ir siendo completada a medida que se armen las demás páginas)
- Wishlists con aplicaciones posibles
- Actual(Presupuesto y control de gastos)
- BitWarden(VaultWarden)(Gestor de contraseñas)
- Beszel(Supervisión del server)
- Freshrss("Agregador" de feeds de RSS, noticias)
- Obsidian-livesync(sincronización entre dispositivos para Obsidian)
- Pairdrop("Airdrop" casero, recomendar LocalShare)
- Seafile vs Nextcloud vs Samba (Para almacenar datos)
- Vikunja (Alternativa de Trello/ticktick/aplicaciones de tareas)
Preparativos
- Instalar linux (ubuntu server, o linux mint)
- Configurar router
- Comprar un dominio
- Apuntar el dominio a la IP (ver DDNS, y ver qué proveedores permiten hacerlo con un cron además de Namecheap)
- Instalar Docker y Docker Compose
- Installar reverse-proxy (caddy)
- Instalar python
Servicios
Navidrome
- Instalar y configurar Navidrome
- Instalar y configurar spotdl
- Instalar python
- Instalar spotDL
- Usar spotDL
- Instalar y configurar slskd
- Aplicaciones compatibles
Jellyfin
- Instalar y configurar Jellyfin
- Guías de instalación y configuración de arr-stack
Cockpit
Qué es Cockpit?
Cockpit es una interfaz visual a través de la cual podemos interactuar con nuestro servidor. Nos permite hacer varias cosas, como revisar el estado del mismo (cuánto CPU o RAM está gastando y en qué), o particularmente, subir o bajar archivos al mismo de manera simple.
Instalar Cockpit
La instalación de cockpit es muy simple. Simplemente tenemos que escribir estos dos comandos:
. /etc/os-release
sudo apt install -t ${VERSION_CODENAME}-backports cockpit
Una vez escritos, cockpit estará instalado. Para acceder, tendríamos que escribir la IP de nuestro servidor en un navegador web, seguido por ":9090". Por ejemplo, si la IP es 192.168.0.134, deberíamos acceder a 192.168.0.134:9090 (para lxs curiosxs, el dos puntos indica a través de qué puerto queremos establecer la conexión con el servidor; Cockpit "escucha" conexiones hechas al puerto 9090.
Una vez que escribimos la dirección, nos recibe esta pantalla de login. Para iniciar sesión, vamos a usar nuestro usuario común de linux.
Una vez adentro, vamos a poder hacer las cosas mencionadas arriba, además de actualizar paquetes y más.
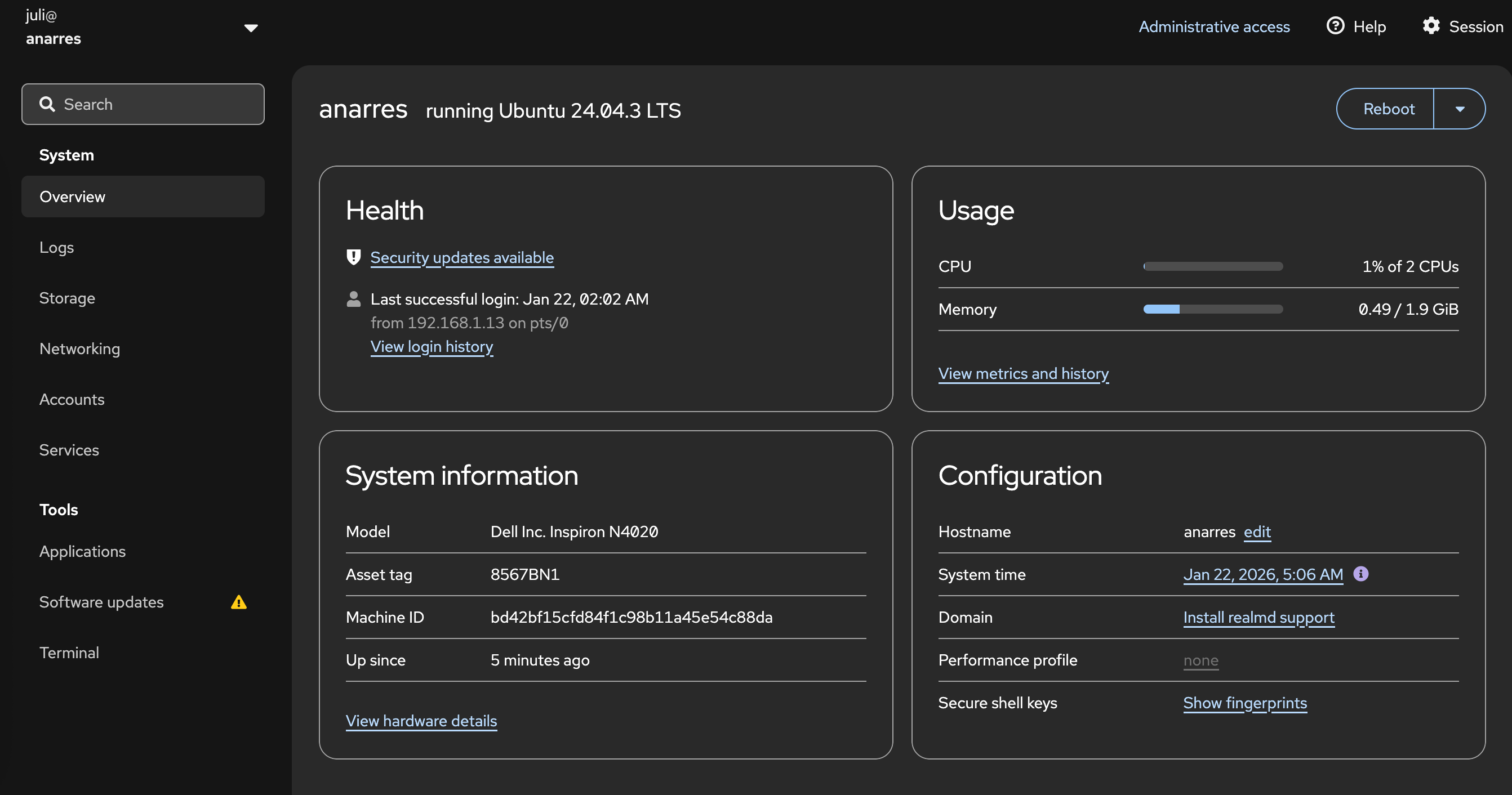
Arreglar bug de conexión a internet
Por cuestiones complejas, suele pasar que cockpit no es capaz de conectarse a internet para bajar paquetes o actualizarlos. La solución a esto consiste en tres pasos:
- Crea el archivo
/etc/NetworkManager/conf.d/10-globally-managed-devices.conf con el comando:sudo nano /etc/NetworkManager/conf.d/10-globally-managed-devices.conf` y escribí el siguiente contenido:
[keyfile]
unmanaged-devices=none
- Escribí el siguiente comando para crear una interfaz de red "de maniquí":
nmcli con add type dummy con-name fake ifname fake0 ip4 1.2.3.4/24 gw4 1.2.3.1
- Reiniciá la computadora (con
sudo reboot)
Después de estos pasos, no deberías tener más este problema.
Instalar extensión "Files"
"Files" o "Cockpit-Files" es una extensión que nos va a permitir cargar y descargar archivos a y desde nuestro servidor de manera simple y con su interfaz gráfica. Para instalarlo, vamos a tener que correr uno por uno estos comandos:
sudo add-apt-repository ppa:pitti/cockpit-files
sudo apt update
sudo apt install cockpit-files
Una vez instalado, si refresheamos o volvemos a entrar a la interfaz. nos vamos a encontrar con una nueva secciíon llamada "File Browser":
Dentro de esta sección vamos a poder manejar los archivos que encontramos en nuestro servidor.